ソフトウェアII 第6回(2025/01/09)
本日のメニュー
- 分割コンパイル想定時の記憶域指定子
- extern 指定子
- static 指定子
- データ構造
- 木構造
- アプリケーション
- ハフマン符号
- ハフマン符号によるデータ圧縮
記憶域指定子
これまで変数が確保されているメモリ領域には3つあることを学びました。
- 静的領域(スタティック領域)
- プログラム開始時から終了まで確保される固定的な領域。グローバル変数を宣言するとこの領域に確保される。
- スタック領域
- 関数が実行される時に使われる領域。今までグローバル変数以外の変数宣言の場合は、この領域に確保されていた。関数が終了するとこの領域に確保されていた変数は自動的に解放される。
- ヒープ領域
- プログラム開始時から存在するが、必要に応じて変数に割り当てたり解放したりが可能な領域。
今回は特に、関数の外で使われている変数などが、分割コンパイルを行う際にどのようになるのかを考えてみましょう。
分割コンパイルにおけるグローバル変数
グローバル変数は関数外で宣言して、それぞれの関数から参照するものでした。これまでのようにファイルが1つなら特に問題はありませんでしたが、分割コンパイル前提の場合はどのようになるでしょうか。
まず単純にヘッダファイルがない場合を考えてみましょう。以下のような2つのファイルに分割するとどうでしょうか?
// main.c : グローバル変数xはきっとどこかにある... そうだ確かfoo.c に ...
#include <stdio.h>
void foo(void);
int main(){
foo();
printf("%d\n", x);
return 0;
}
// foo.c : ここにグローバル変数x を書いておこう
int x = 0;
void foo(){
x += 1024;
}
これを以下の手順でコンパイルしてみます。
# まず foo.c をコンパイル : OK
gcc -c foo.c
# 次にmain.c をコンパイル.....
gcc -c main.c
main.c のコンパイルでエラーがでると思います。
これはmain.c からは、変数x を知り得ないことに起因します。ではひとまずmain.c に書いてみましょう。
// main.c : グローバル変数xはこっちにも書いておこう
#include <stdio.h>
void foo(void);
int x = 0; // ここにグローバルで書いておこう
int main(){
foo();
printf("%d\n", x);
return 0;
}
foo.c はコンパイル済みなのでmain.c をコンパイルします
# main.c をコンパイル : 今度はコンパイルできる
gcc -c main.c
# オブジェクトファイルをリンク....
gcc -o test main.o foo.o
リンクをするとエラーがでます。エラーの内容を読むとxが多重に定義されているとあります。
以上をまとめると分割コンパイルではグローバル変数を扱う場合は、このファイルでは定義はないですが、グローバル変数はあります という状態にする必要があります。変数を使える状態にするには宣言と定義がありました。これは関数におけるプロトタイプ宣言と実際の定義の関係と同じです。
- 宣言
- どのような変数があるかを示す。具体的にどういう値かは特に触れない。
- 定義
- 宣言された変数が具体的にどういう値をとるかを設定する。
分割コンパイルの考え方では変数の宣言はヘッダファイルに、変数の定義は実装するCファイルに書くようにします。この宣言時に、「この変数の定義はどこか別のところにあるよ」と示すのがextern指定子です。
extern指定子
extern指定子 は、変数の宣言時に用いて、別の場所に定義が存在することを明示する指定子です。 ヘッダファイルがない場合でも、宣言と定義を分けてその役割を明示します。extern に関わるポイントは以下です。
- externは宣言のみに用いるため、extern指定子と定義は同時には行わない。
- extern宣言を行われた変数が、リンク時にどの場所でも定義されていない場合はエラー。
- extern を伴わない宣言 は暗黙的にexternがついたものとみなされる。
実は最後が若干曲者で、これがextern指定子を非常にわかりにくくしていますが、順に説明していきます。
まずはヘッダファイルを用いずに先ほどまでのコードにextern 指定子をつけてみましょう。
// main.c :
#include <stdio.h>
void foo(void);
extern int x; // どこかに定義があります
int main(){
foo();
printf("%d\n", x);
return 0;
}
// foo.c :
int x = 0; // ここでグローバル変数を定義
void foo(){
x += 1024;
}
このようにすると無事にコンパイルできるようになります。
# foo.c をコンパイル
gcc -c foo.c
# main.c をコンパイル : 今度はコンパイルできる
gcc -c main.c
# オブジェクトファイルをリンク....
gcc -o test main.o foo.o
# 実行
./test
サンプルコード
ここからサンプルコードを使ってヘッダファイルを分割した場合を見てみましょう。
# ダウンロード(wgetの場合)
wget https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/extern-example.tar.gz
# ダウンロード(curlの場合)
curl -O https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/extern-example.tar.gz
# 展開
tar xvzf extern-example.tar.gz
cd extern-example
このソースは以下のコードで構成されています。
// foo.h
#pragma once
void foo(void);
extern int x;
// foo.c
#include "foo.h"
void foo(void)
{
x += 1024;
}
// main.c
#include <stdio.h>
#include <stdlib.h>
#include "foo.h"
int main(void)
{
foo();
printf("%d\n",x);
return EXIT_SUCCESS;
}
上記はヘッダファイルで、extern指定子のついた変数宣言が行われ、これが各Cファイルにinclude されています。
以下に取り組みましょう。
- make してコンパイルしてみましょう。
- foo.c にグローバル変数の定義を追加してコンパイルしてみましょう。
考察
一つ目の結果から、extern 宣言された変数が未定義である旨のエラーが出ていることがわかります。このようにして使うべき変数の未定義を正しく検出することができます。これを二つ目のように修正することで正しくコードが動くことがわかります。最後に
- ヘッダファイルでのextern指定子を除く
- foo.c で int x ; と定義なしで宣言する
としてみましょう。動きます。 これは
- externを伴わない宣言が暗黙的に外部宣言とみなされる
- グローバル変数は未定義時に0で初期化される=暗黙的に定義される
static 指定子
static 指定子は関数の中で使う場合と関数の外で使う場合で異なる意味になりますが、分割コンパイルにおいては特に重要な指定子です。
関数内で使うstatic指定子
関数内でstatic指定子を用いる場合は、変数のメモリ領域を通常のスタック領域ではなく静的領域を用いることを示しています。スタック領域の変数は関数の実行のたびに確保・解放がされますが、静的領域に置かれることで、プログラムの開始から終了まで保持されます。なおstatic変数の定義は、最初だけ用いられます。
#include <stdio.h>
int count(){
static int c = 0;
c++;
return c;
}
int main(){
for (int i = 0 ; i < 10 ; i++){
printf("%d\n", count());
}
return 0;
}
以下に取り組みましょう。
- 上記のコードを写経して、コンパイル・実行してみましょう。
- count()内の変数c の static宣言をstatic int c; c = 0; と2行にわたってかくとどのようか確かめましょう。
関数の外で使うstatic指定子
関数外でのstatic指定子は意味が異なります。分割コンパイルにおいて実装のCファイルでstatic 指定子のついた関数や変数は、そのファイルにおいてのみ有効になります。このことを「内部リンケージを持つ」といいます。内部リンケージを持つ変数や関数は該当する分割コンパイルファイルのみで有効になります。すなわち逆に言えばstatic 宣言がついていれば、同じ名前の変数や関数が複数のファイルに存在してもよい状態になります。static指定子は特定の実装ファイルの中だけで用いるローカルな定義をすることができます。これによって機能を適切に隠蔽することができます。static指定子をこの目的で用いる注意点はstatic指定子のついた関数はヘッダファイルに記述しない : 外部公開しない前提だから という点です。
データ構造
今日は木構造というデータ構造に触れてみましょう。木構造は言葉的には「木のような構造」なのですが、グラフ理論の言葉を使うと「連結で閉路を持たないグラフ」ということが言えます。プログラムやアルゴリズムで取り扱う場合は、一番「上」に相当するノードを考え、そこから順次連結が伸びていく構造を考えます(根つき木)。
木構造
木構造ではあるノード(root nodeという)を出発点として各ノードが複数の子ノードを有する連結関係が再帰的につながっています。木構造ではあるノードに着目すると(rootを除いて)親が存在し、親を介した兄弟ノード、および自身の子ノードを有します(子ノードがない場合はleaf node)という。
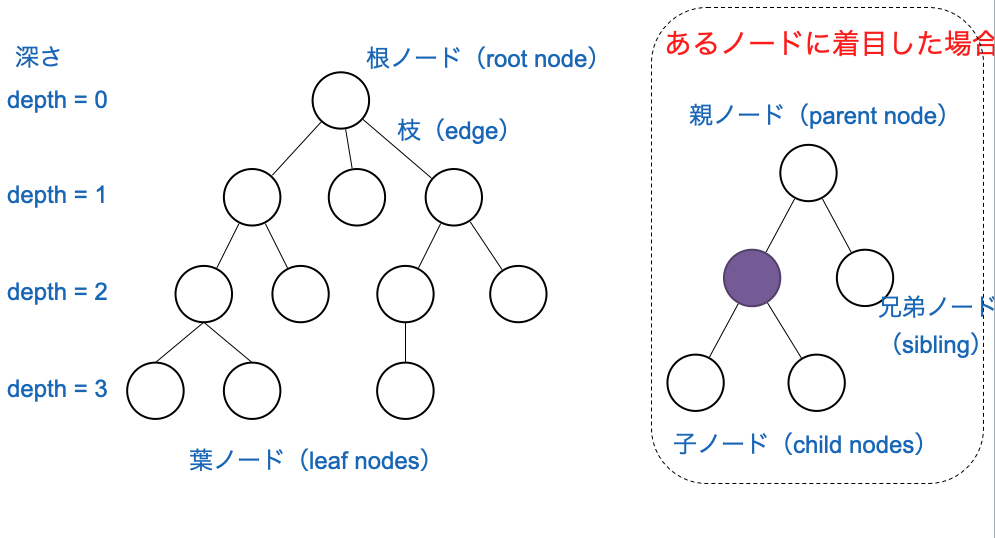
木構造の中で特にアルゴリズム的に重要なものの一つが二分木(binary tree)です。二分木は各ノードが最大でも2つの子ノードしか持たない木 です。アルゴリズムを考える際の全ての木は二分木に変換して考えることができるため、非常に重要な概念です。
二分木のなかでも完全二分木というものがあります。これは最下段以外のノードが全て埋まっており、最下段については左から隙間なくうまっている状態の二分木を指します。
二分木の実装
二分木を実装する場合は、線形リストと同様、自己参照構造体を用いて実装します。 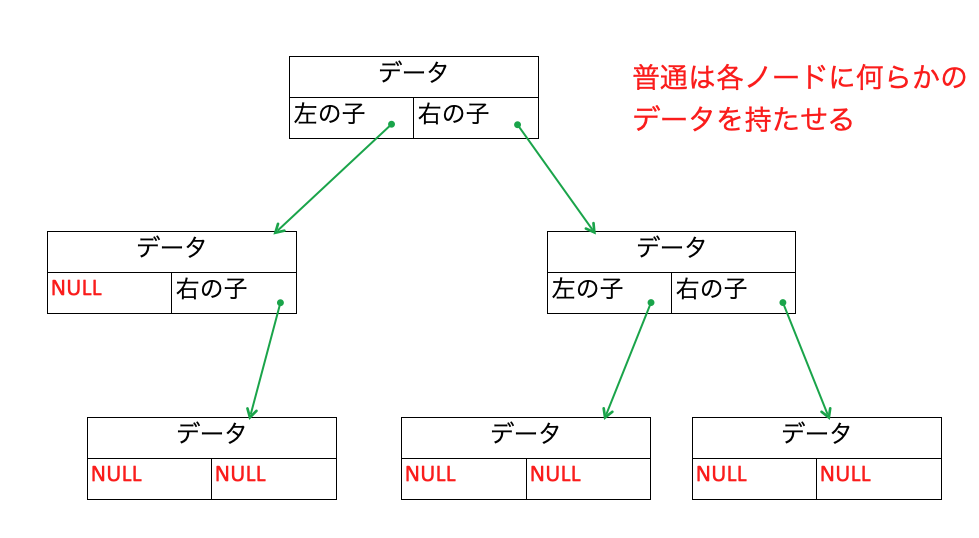
struct node {
int value; // データ
struct node *parent;
struct node *left;
struct node *right;
}
なお親か子のどちらかのポインタしか持たないことも多いです。一方対応するノードが存在しない場合はポインタでNULLを指定するようにします。
木構造データへのアクセス
木構造に含まれる全てのノードを訪れることを考えます。このとき木に含まれる全てのデータを表示することを考えましょう。この全てのノードへの訪問を**走査(traversal)**といいます。走査の順序には以下の3種類が考えられます。
- 行きがけ順 (preorder)
- 親 -> 左の子 -> 右の子 の再帰
- 通りがけ順 (inorder)
- 左の子 -> 親 -> 右の子 の再帰
- 帰りがけ順 (postorder)
- 左の子 -> 右の子 -> 親 の再帰
例えば「行きがけ順」で走査をすることで深さ優先の探索(search)を行うことができます。
サンプルコード
木構造の走査を行ってみましょう。
# wget
wget https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/traverse.tar.gz
# curl
curl -O https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/traverse.tar.gz
# 展開
tar xvzf traverse.tar.gz
cd traverse
サンプルコードでは、10個のノードを考えています。まだ連結はしていません。以下のような木のサンプルを考えます。 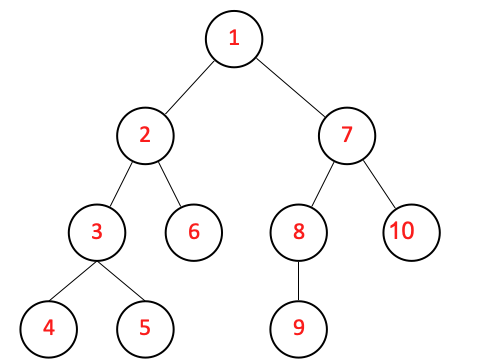
以下に取り組んでみましょう。
- 上記の図のような木を作成するようにmain.c を修正してみましょう。
- src にあるtraverse関数を行きがけ順で走査するように完成させて実行してみましょう(ヒント: 再帰を用いる)。
- 数字が 1 から順に 10 まで表示されれば成功
- その他の走査順序も考えてみましょう。
Let's try 一例
[追記] Let's try の一例です。
main.c
木の接続関係を表すため、構造体内のポインタに適切な値を代入します。今回はmain関数で確保された構造体をつないでいる(mallocされたものではない)ことに注意。int main(int argc, char **argv)
{
// ノードを10個ほど定義
Node n1 = { .value = 1, .left = NULL, .right = NULL};
Node n2 = { .value = 2, .left = NULL, .right = NULL };
Node n3 = { .value = 3, .left = NULL, .right = NULL };
Node n4 = { .value = 4, .left = NULL, .right = NULL };
Node n5 = { .value = 5, .left = NULL, .right = NULL };
Node n6 = { .value = 6, .left = NULL, .right = NULL };
Node n7 = { .value = 7, .left = NULL, .right = NULL };
Node n8 = { .value = 8, .left = NULL, .right = NULL };
Node n9 = { .value = 9, .left = NULL, .right = NULL };
Node n10 = { .value =10, .left = NULL, .right = NULL };
// 木を繋いでみる。木の形はページ参照
n1.left = &n2; n1.right = &n7;
n2.left = &n3; n2.right = &n6;
n7.left = &n8; n7.right = &n10;
n3.left = &n4; n3.right = &n5;
n8.left = &n9;
// 走査する
traverse(&n1);
return EXIT_SUCCESS;
}
traverse.c
行きがけ順なので、親を表示後に左、右の子の順に再帰すればよい。void traverse(const Node *n)
{
if (n == NULL) return;
printf("value=%d\n", n->value);
traverse(n->left);
traverse(n->right);
}
二分木構造の応用
二分木は重要なデータ構造であり、様々な応用があります。
- 構文解析
- 例えば3+4-2*3 のような式を解析する場合に、数字をリーフノード、途中のノードに演算子を考えることで、数式を木構造で表現できます。このような木を構文解析木と呼びます
- 二分探索木
- 二分木のデータ間に制約条件を与えることで、効率的なデータ管理を実現できます。二分探索木では全てのノードで左の子孫の値<親の値<右の子孫の値の関係が成り立つようにすることで、ある値を持つノードをO(log n) の平均計算量でみつけることができます
- 二分ヒープ
- 二分ヒープでは全てのノードで親の値>=子の値の関係が成り立つように木を構成します。これによりあるデータ群(部分木に相当)の中での最大値をすぐに取り出すことが可能になります。
アプリケーション
二分木を用いたアプリケーションとして、文字データのハフマン符号化を考えてみましょう。
ハフマン符号
コンピュータで文字を扱う場合、各文字に整数が割り当てられているのはすでに皆さん何度もやってきたと思います。文字シンボル(char型)の場合は、正の整数が割り当てられているので全てのシンボルは実質7ビットで表されていることになります。ASCIIコードはこの対応関係を記述したものになります。
| シンボルの例 | 16進数 | 2進数 |
|---|---|---|
| [空白] | 0x20 | 0100000 |
| A | 0x41 | 1000001 |
| B | 0x42 | 1000010 |
| z | 0x7a | 1111010 |
符号化
実際のシンボルには使われる頻度に基づく偏りが存在します。一旦ASCIIコードから離れて、あるシンボル系列ABACABAAD を考えてみましょう。出現する4つのシンボルにコード語として01の値を付与することを考えます。まず最初に、以下の符号化を行うとします。
| シンボル | コード語 |
|---|---|
| A | 00 |
| B | 01 |
| C | 10 |
| D | 11 |
このとき与えられたシンボル系列は000100100001000011 となり18ビットです。次に以下の符号表を考えます。
| シンボル | コード語 |
|---|---|
| A | 0 |
| B | 10 |
| C | 110 |
| D | 111 |
この表を用いた場合はシンボル系列は010011001000111 は15ビットとなり効率的に表現することができます。これは多く出現するシンボルに短い符号長のコードを割り当て、出現頻度の少ないシンボルに長い符号長のコードを割り当てることで実現されます。
接頭符号(prefix code)
各シンボルのコード語の先頭に着目します。どのコード語も他のコード語の語頭になっていない符号を接頭符号といいます。接頭符号でないと、大量のビット列からシンボルを復号する際に問題となります。先程の短い符号長を実現した符号表は接頭符号の条件を満たします。一方以下の符号はコード語の一部が別のコード語の語頭となっており、条件を満たしません。
| シンボル | コード語 |
|---|---|
| A | 0 |
| B | 10 |
| C | 100 |
| D | 111 |
ハフマン符号
ハフマン符号は出現頻度の高いシンボルに短いコード語を割り当てていく接頭符号であり、整数の符号長の制約のもとでは最適な符号を構成できます。さきほどの例では下図のような木構造(ハフマン木という)を通して、符号を得ることができます。
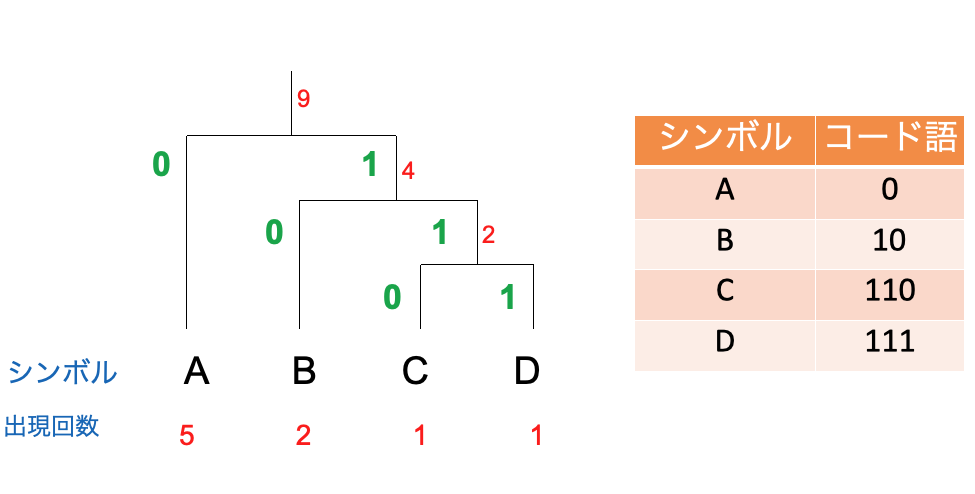
ハフマン符号の構成手順
ハフマン符号の構成手順は以下のようになります。
木の作成
- 各シンボルの出現回数を数える
- 出現回数が最も小さい2つのシンボルを統合し、新たな(ダミー)シンボルを作成
- 新たなシンボルの出現回数は、統合された2つのシンボルの出現回数の和とする
- シンボルが1つになるまで 2 に戻り繰り返す
符号の作成
- すべての枝別れに対して、 0(左の枝)と 1(右の枝)のビットを割り振る
- このとき左右と0/1 の対応はどちらでも構わない
- 個々のシンボルに対して、ルートからの経路のビット列としてコード語が得られる
サンプルプログラム
ハフマン符号を構成するサンプルプログラムの雛形を見てみましょう。
# wget
wget https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/huffman.tar.gz
# curl
curl -O https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/huffman.tar.gz
# 展開
tar xvzf huffman.tar.gz
cd huffman
# コンパイル
make
# 実行
bin/huffman
現状使い方が表示されます。コンパイル時に警告がでますが、穴埋めコードが未完成のためです。現状同梱されているnews.txt を引数として渡しても、木は構成されません。
実装のポイント
ハフマン符号の構成手順に従ってLet's try を行ってください。修正すべき関数はsrc/encode.c に集約されています。まずはsrc/encode.c 冒頭のstatic宣言されたプロトタイプ宣言をざっと読んでみましょう。
なお冒頭のハフマン符号の構成例では次々とリーフノードを追加していましたが、実際のデータではリーフ同士の統合 や ダミーノード同士の統合 など全てのケースがあり得ることに注意してください。
以下に取り組んでみましょう。
- count_symbols() を完成させて、シンボルの出現回数を数えるように修正しましょう。
- build_tree() を完成させましょう。
- ダミーノードのデータはダミー用のシンボル(-1)とする
Let's try の一例は講義中に示します。
Let's try 一例
[講義後追記] Let's try の一例です。
count_symbols()
C言語の場合、特定の文字要素の出現回数を数える際によく使うテクニックにその文字を整数型のインデックスとして、配列の値をインクリメントしていく方法があります。今回はそれで実装します。この例では改行込みの1Byte単位なので、読み込みはシンプルにfgetc を用いています。この書き方の場合、バイナリデータも単純に1バイトずつ切り出されます。 最初のfopen でバイナリモードを指定している理由は、Windowsでテキストモードの場合、ファイル中に0x1a があると、これをEOFとして止まってしまうことによります。static void count_symbols(const char *filename)
{
FILE *fp = fopen(filename, "rb");
if (fp == NULL) {
fprintf(stderr, "error: cannot open %s\n", filename);
exit(1);
}
int c;
while( ( c = fgetc(fp)) != EOF ){
symbol_count[c]++;
}
fclose(fp);
}
build_tree()
配布コードのwhile文内を示します。ポイントは別途実装しているpop_minにより、用意している配列nodepの末尾の位置(n)が変わることと、統合ノードを作成後、その末尾に統合ノード追加することです。一回のループでnの値は結局1つずつ小さくなるので、いずれはwhile文の終了条件に到達します。const int dummy = -1; // ダミー用のsymbol を用意しておく
while (n >= 2) {
Node *node1 = pop_min(&n, nodep);
Node *node2 = pop_min(&n, nodep);
// Create a new node
// pop_min によりnはnodep終端を変更しているので、終端に突っ込んで一つ増やす
nodep[n++] = create_node(dummy, node1->count + node2->count, node1, node2);
}
課題(締切: 01/29)
- traverse_tree() 関数を修正し、各シンボルに対するコード語を求めよ
- コード語はまずは文字列(01の羅列)として表示するだけでよい
- ツリー構造がわかるように表示を工夫すること
- 改行についてはそのまま表示すると表示が崩れるため、'LF' や '\n'を表示するなどすること
huffman0というディレクトリを作成し、makeして実行可能になるようにすること
- [発展課題] 圧縮・解凍ツールとして動作するよう拡張せよ
huffman1というディレクトリを作成し、makeして実行可能になるようにする- 工夫として以下のようなことが考えられる
- 実際にビット列にすることでファイルサイズが元のファイルより小さくなるようにする
- 符号化用のテーブルも同時に圧縮されたファイルに組み込む
- 必ずしも完全に動作している必要はない
- 圧縮しかできない等でもよい
- どんな機能が実装できたかについてもファイルを同梱し簡単に説明すること
- ハフマン符号による圧縮はzipなどでも用いられる。これらの実装に挑戦してみる(deflateというキーワードで調べてみる)のも面白い
ツリー構造の表示は例えば、UNIX でディレクトリ構造を表示するtree コマンドの以下のような表示を参考にするとよい。ただし以下ではユニコード文字が用いられているので、これを避ける場合は例えば+ や - を駆使して表示することが考えられる。
.
├── bin
├── include
│ └── qsort.h
├── lib
└── src
├── main.c
└── qsort_lib.c
提出方法
- UTOLにて提出する
- 全てのプログラム/ファイルをまとめ、zip またはtar.gzで圧縮し提出
- 必ずREADME.md を同梱し、やった内容を簡潔に記述する
- ファイル名は
SOFT-01-09-NNNNNNNN.zipまたはSOFT-01-09-NNNNNNNN.tar.gzとする- NNNNNNNN部分は学籍番号(ハイフンは除く)
- JについてはJ??????? のようにする
- 課題について
- 基本課題は毎回提出
- 発展課題は成績計算に全6回中上位3回分を採用する
連絡事項
次回は1/23です。