ソフトウェアII 第5回(2024/12/26)
本日のメニュー
- バイナリデータの読み書き
- 関数の再帰呼び出し
- 組み合わせ最適化問題
- ナップサック問題
- 巡回セールスマン問題
- 課題について
準備
サンプルコードをダウンロードしておきましょう。
# wget の場合
wget https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/soft2-lec05-src.tar.gz
# curl の場合
curl -O https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/soft2-lec05-src.tar.gz
ダウンロード後は解凍して、そのディレクトリに入ってください。
tar xvzf soft2-lec05-src.tar.gz
cd soft2-lec05-src
バイナリデータの読み書き
バイナリデータとは何か
これまでファイルを介したデータの入出力においては、人間が読める「テキストデータ」を扱ってきました。今回は「バイナリデータ」の読み書きを扱いましょう。バイナリデータを字の通り解釈すると、2進数表現で記述されたデータということになりますが、それはすなわちコンピュータで扱うデータ全てです。広義ではテキストデータもバイナリデータと考えることができますが、通常テキストデータは人間が読んで理解できるいわゆる文字列の並んだデータのことを指し(プレーンテキストともいう)、バイナリデータは人間には一見して読み取れないがコンピュータが直接読み取りやすいデータを指すことが多いです(「目grep」というスキルを用いてバイナリを読み取る人間もいますがここでは扱いません)。特に数値データの読み書きに着目した場合、テキストファイルではなくバイナリファイルを取り扱うことは以下の利点があります。
- 文字列から数字への変換に伴う精度劣化の可能性がない
- ファイルサイズが縮小される
- 通常テキストを読み取るより速度面で速い
C言語のバイナリ入出力
C言語でファイル入出力を扱う基本について確認します。ファイルを開いたり、閉じたりする関数についてはテキスト、バイナリ共通です。
#include <stdio.h>
FILE *fopen(char *name, char *mode); // ファイルを開く
int fclose(FILE *fp); // ファイルを閉じる
ただし、読み書きのモードを表す際、バイナリを扱う場合にはb を追加してrb(読み込みの場合)またはwb(書き込みの場合)としておく方がよいです。MacやLinux ではb の有無によって結果が変わることはありませんが、Windows の場合は注意が必要です。Windows の場合、b が存在しない場合はテキストモードと判断し、改行の置換と0x1a をEOFとみなすという処理が入ります。b をつけるとバイナリモードとなり、変換なしでファイルを読み書きします。このようにWindowsの場合のみb の有無によってファイルの読み書きの挙動が異なるため、全てのOSで適切に動作する可搬性の高いコードという観点から
- テキストの読み書きの場合は
bをつけない - バイナリの読み書きの場合は
bをつける
と覚えておくとよいです。
これまでの課題を通してテキストファイルの読み書きをする場合は、例えば1行ごとの読み取りでfgets() を用いたりしていたと思います。バイナリファイルを直接読みとるときにポイントになるのは
- どのファイルから読み取るか
- ファイルから読み取ったデータをメモリのどこに書き込むか
- どのサイズのデータをいくつ読み取るか
です。一方、変数や配列などのデータをファイルに書き込む場合は
- どのファイルへ書き込むか
- メモリのどこを読み取ってファイルに書き込むか
- どれぐらいのサイズを読み取って書き込むか
の3点です。これらの情報をもとにバイナリの読み書きをするのが以下のfread()とfwrite() です。
#include <stdio.h>
// ファイルからsizeバイトのデータnitems個分を指定のアドレスに読み込む
size_t fread(void *data, size_t size, size_t nitems, FILE *fp);
// 指定アドレスからsizeバイトのデータnitems個分を読み取り、ファイルに書き出す
size_t fwrite(void *data, size_t size, size_t nitems, FILE *fp);
例えば16バイトのデータを読み取りたい場合、4バイトのデータが4つなのか、8バイトのデータが2つなのかによって、呼び出し方は変わりますが、読み出された後の先頭アドレスから16バイトのデータそのものには変化はありません。例えばその先頭アドレスを受け取るポインタの型が異なれば、異なるデータ型で異なる個数のデータとして解釈可能です。
なお、それぞれの関数の返り値は「読み込み/書き込みに成功した個数」となります。この情報を利用することで例えば「8バイトデータを3個ずつ順に読み取ろうとしたが最後だけ2個しか読み取れずファイル終端を迎えた」などの状況にも適切に対応することができます。
バイナリ読み込みのサンプル
まずは簡単な例としてテキストファイルをfread を使って読み取りましょう。テキストファイルも単なるデータの並びとして扱うことができます。
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
int main(int argc, char **argv){
if (argc != 2){
fprintf(stderr, "usage: %s filename\n", argv[0]);
return EXIT_FAILURE;
}
FILE *fp;
if ( (fp = fopen(argv[1],"rb")) == NULL){
// fopen は失敗した場合 errno の変数をセットする
// perror は errno の番号に対応したメッセージを返してくれる
perror(argv[1]);
return EXIT_FAILURE;
}
// 100バイトのchar配列(スタック領域)
char buf[100];
// 1バイトを100個分読み出す。rsize には読み出した個数が格納される
size_t rsize = fread(buf, sizeof(char), 100, fp);
printf("%zu Byte read\n", rsize);
// 文字列だと解釈したい場合は終端記号\0を追加
// この作業は必須ではない
if (rsize < 100){
buf[rsize] = '\0';
printf("%s",buf);
}
return EXIT_SUCCESS;
}
上記のプログラムを写経・コンパイルし、helloworld.txt を引数として実行してみましょう。
fread は先頭アドレスを引数にとります。このメモリ領域は事前に確保されている必要があります。上記の例ではスタック領域に確保されていますし、動的に読み込むサイズを変更する場合はmalloc を使ってヒープ領域に確保してから使用します。
バイナリ書き込みのサンプル
サンプルファイルのwritebinaryfile.c は1000万個のdoubleデータを用意しテキスト、バイナリの2通りに出力するプログラムです。コンパイルして実行し、できた2つのファイルサイズを比較してみましょう。
# コンパイル
gcc -o writebinaryfile writebinaryfile.c
# 実行: 第一引数がテキストファイル名、第二引数がバイナリファイル名
./writebinaryfile data.txt data.dat
以下に取り組んでみましょう。
- さきほど出力したテキストファイルを読み取り、double型の配列にセットするプログラムを書いてみましょう。
- さきほど出力したバイナリファイルを読み取り、double型の配列をセットするプログラムを書いてみましょう。
- ヒント: fread による読み取り
- 先頭の個数情報を利用して適切に
mallocする
- 実行時間を比較してみましょう
- 実行時間計測にはプログラムの前に
timeとつけます
- 実行時間計測にはプログラムの前に
UNIXにおけるtime コマンドはプログラムの実行時間を計測するプログラムです。
time ./readbinaryfile data.dat
のように使います。
Let's try 一例
[講義後追記] テキストおよびバイナリの読み込みの一例は以下からダウンロードできます。
# wget
wget https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/soft2-lec05-fileread.tar.gz
# curl
curl -O https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/soft2-lec05-fileread.tar.gz
書き出しのところで出力したテキスト/バイナリファイルを読み取り、速度を比較してみましょう。
# data.txt および data.dat はディレクトリにコピーされていると仮定
# コンパイル
gcc -o readbinaryfile readbinaryfile.c
gcc -o readtextfile readtextfile.c
# 実行と計測
time ./readtextfile data.txt
time ./readbinaryfile data.dat
バイナリファイルの読み書きの実際
実際に世の中に存在するファイル形式では「ヘッダ部分」と「データ部分」が存在することがほとんどです。例えば音声ファイル形式の一つであるWAVファイルは、通常先頭44バイトにファイルサイズやチャンネル数などの情報が規定の方法で存在し、その後実際の音声データが所定のバイナリ(short型整数やfloat型の実数)で保存されています。それぞれのファイルの入出力を自作する場合は
- ヘッダ部分を読み取り、その後の実データを読み取る準備をする(mallocによるメモリ領域確保や構造体へのヘッダ情報の代入など)
- 実データ部分を読み取り、確保したメモリ領域にセットする
の機能を満たすように設計することになります。
バイトオーダについて
バイナリデータの読み書きに関連して、計算機におけるビット表現、バイト表現がどのようになっているかについて少し学んでおきましょう。以下のプログラムはunsigned char型(1バイト)の変数に1を代入し、そのビット表現を出力しています。
#include <stdio.h>
int main(void){
unsigned char a = 1;
for (int b = 0 ; b < 8 ; b++){
printf("%d", (a & 1 << (7-b))?1:0);
}
printf("\n");
return 0;
}
次にunsigned short型(2バイト)の変数に1を代入したあと、そのアドレス領域をunsigned char型2つ分 と思って読むとどうなるでしょうか?
#include <stdio.h>
int main(void){
unsigned short a = 1;
// unsigned char型ポインタを用意する
// 上記の先頭アドレスをキャストして代入
unsigned char *p = (unsigned char*)&a;
for (int i = 0 ; i < sizeof(unsigned short) ; i++){
printf("%p\n", p+i);
for (int b = 0 ; b < 8 ; b++){
printf("%d", (p[i] & 1 << (7-b))?1:0);
}
printf("\n");
}
return 0;
}
上記のプログラムを写経・コンパイルし実行しましょう
考察
一つ目のプログラムの結果は右端に1ビット存在し、整数1の2進数表現として妥当な結果が得られているかと思います。2つ目のプログラムの結果はどうでしょう。この結果はCPUに依存しますが、おそらくほとんどの皆さんが使っていると考えられるIntelのCPU(x86)環境では、最初のバイトの方に1が立ち、2番目のバイトが0になっているかと思います。このように1バイトを超える多バイトのデータをどの順番で格納するかをバイトオーダ と言います。Intel x86プロセッサの場合は、リトルエンディアンと呼ばれる方式で、最下位ビットの属するバイト(Least Significant Byte: LSB)が若いアドレスに格納されます。逆に最上位ビットの属するバイト(Most Significant Byte: MSB)から順に若いアドレスに格納する方式をビッグエンディアンといい、かつてのMacのCPUとして使われていたPowerPC などはビッグエンディアンを採用したコードが多く使われていました。なおJava を使う場合はJavaの仮想マシンはビッグエンディアンでバイナリを取り扱うのがデフォルトのようです。バイトオーダは普段のプログラミングで意識することは少ないですが、ネットワークデータを扱ったり、ファイル形式によっては特定のエンディアンを前提にしているケースがあります。コンピュータへのデータの格納方式の違いとして頭の片隅に入れておくとよいでしょう。
floatを様々な形式で表示してみよう
浮動小数点を様々な形式で表示してみましょう。C言語の浮動小数点は実は様々な形式で指定することができます。C言語の浮動小数点はIEEE754と呼ばれる標準規格に基づいています。特に16進数浮動小数点表記を用いるとそのビット構造との対応が非常にわかりやすくなります。10進数表記では厳密には表せないものを表記可能です。
// print_float.c
#include <stdio.h>
int main(void){
float f = 0.0000102411234;
printf("%%f: %f\n",f);
printf("%%.8f: %.8f\n",f);
printf("%%e: %e\n", f);
printf("%%.8e: %.8e\n", f);
printf("%%a: %a\n", f);
printf("%%.8a: %.8a\n",f);
return 0;
}
関数の再帰呼び出し
再帰呼び出し
ある手続きの中で自分自身を呼び出すことを再帰呼び出しと言います。C言語の場合は関数で手続きを表現するので、引数を変えながら関数内で自分自身を呼び出すのが再帰です。実は以前のペイントソフトでは、interpret_command() のundo部分で、再度interpret_command() が呼び出されており、再帰呼び出しがされていたことになります。一例として、以下のような関数を考えます。
// 階乗を求める関数
int factorial(int n){
if ( n == 0 ) return 1;
return n * factorial(n-1);
}
この関数の実行過程は以下のようになります。関数のreturn 部分で、新しい引数で関数が呼ばれていきます。終端で値が確定すると、次々と呼び出し元に戻り、最終的に最初の呼び出しの値が確定します。 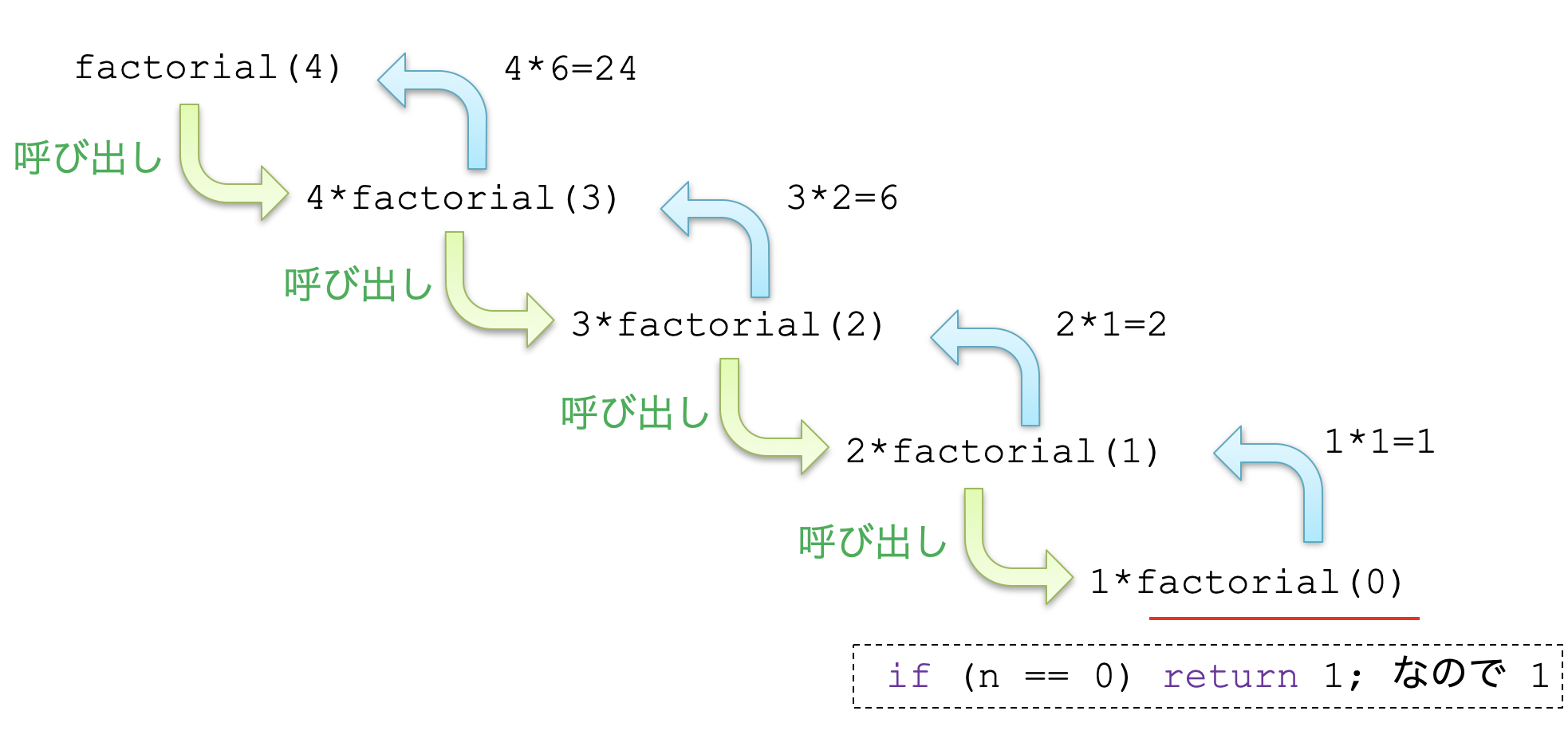
再帰呼び出しの特徴
再帰呼び出しは基本的には等価な繰り返し処理で書くことが可能です。また実行速度面では繰り返しで記述した方が高速な場合が多いです。しかし一方、再帰呼び出しを用いることでアルゴリズムを簡潔に実装できる場合があります。以下はユークリッドの互除法と呼ばれる最大公約数を計算する効率的なアルゴリズムです。再帰関数を用いることで簡潔な記述を実現できていることがわかります。
// while version of euclid gcd
int euclid(int m, int n){
int remainder;
while ( (remainder = m%n) != 0){
m = n;
n = remainder;
}
return n;
}
// recursion version of euclid gcd
int euclid(int m, int n){
int remainder = m % n;
return (!remainder) ? n : euclid(n, remainder);
}
再帰関数の停止条件
再帰を実装する場合に注意すべき点として、必ず再帰を停止する部分を書いておく ということがあります。これは漸化式における初期値に相当すると考えてください。このような停止条件を書かない場合、無限に関数が呼び出されることになります。
試しに止まらない再帰を書いてみましょう。どうなるでしょうか。
#include <stdio.h>
void test (int *a){
printf("%d\n", (*a)++);
test(a);
}
int main(void){
int a = 0;
test(&a);
return 0;
}
上記のプログラムを写経・コンパイルし実行してみましょう。
考察
上記のプログラムは呼び出した回数を表示しながら最終的にSegmentation fault で終了すると思います。これは前回の講義でも登場したスタック領域のサイズに関係します。再帰関数を呼び出す際には、呼び出す際の変数セットをコピーし、かつ呼び出し終了後に戻ってくる場所を順次記録していきます。この情報はスタック領域に積み上げられていき、関数の呼び出しが終了するたびに、それぞれの関数呼び出しに対応するメモリ領域が解放され、スタックから除かれます。停止条件が記述されていない再帰では、いずれスタック領域の限界を超えてしまう(スタックオーバーフローする)ために、Segmentation fault で終了することになります。組み合わせ最適化: ナップサック問題
今日は組み合わせ最適化問題を扱います。組み合わせ最適化問題とは、解が「順序」や「割り当て」といった組み合わせ的な構造をもっており、ある基準に基づいて最良の解を探索する問題をいいます。
ナップサック問題
ナップサック問題は容量の決まったナップサックと、重さと価値が決まった品物のリストが与えられたときに、ナップサックの限界の重さの制約のもとで品物の価値の合計を最大化する問題です。リスト中の品物がそれぞれ1つだけで、それらを入れるかどうかを決める問題を0-1ナップサック問題といい、以下の式で定式化されます。
$$ {\rm max} \sum_{i=1}^n v_i x_i ~~~ {\rm subject\ to}~ \sum_{i=1}^n w_ix_i \le W, x_i \in (0,1)$$
ナップサック問題は計算の複雑性を議論するときに扱われる非常に有名かつ重要な問題です。
全探索による解法
品物の価値や重さを整数とした整数計画問題として考えると、ナップサック問題には効率的な解法がいくつか知られています。しかし、ここではそれらにトライする前に、再帰関数を用いながら全探索する若干愚直なアプローチをとってみます。すなわち個々の品物の「入れる」「入れない」の全ての組み合わせを考えてみます。
サンプルプログラム
サンプルプログラムをコンパイルして実行してみましょう。
# soft2-lec05-src にいる前提
cd knapsack
# コンパイル
make
# 実行: 第一引数が品物の個数 第二引数が重さの制約
bin/knapsack 10 70.0
結果として全ての解候補が表示され、そのうち重さ制限に違反するものにNGが表示されているはずです。
プログラム解説
ファイルの全体像
全体構造は
- include以下の3つのヘッダファイル
- item.h
- 重さと価値をメンバにもつItem構造体のtypedef
- Item構造体の動的配列とその個数を保持するItemset構造体のtypedef
- Item/Itemset構造体に関連する関数のプロトタイプ宣言
- search.h
- 探索に関する
solve()およびsearch()のプロトタイプ宣言
- 探索に関する
- util.h
- 引数からの整数および実数値読み取り関数(strtolおよびstrtodのラッパー)
- item.h
- src以下
- 上記の実装とmain.c
のようになっています。
mainの構造
まずmain関数の構造としては
- コマンドライン引数で品物の数と容量を決める
- 個々の品物の価値、重さはランダムに決める
- solve() 関数を呼び出す
という流れで実行されています。
search関数について
search関数では「 i 番目以降の品物の「入れない」/「入れる」の全ての組み合わせを考えた場合の、品物の合計価値の最大値」を返します。現在着目している品物を入れるか入れないかの2通りについて異なる引数パターンで再帰的にsearch関数を呼び出すことで全探索を実現しています。このとき本来重さ制限のためにすでに探索する必要のない候補も探索しています。
// 再帰的な探索関数
double search(int index, const Itemset *list, double capacity, unsigned char *flags, double sum_v, double sum_w) {
size_t max_index = get_nitem(list);
assert(index >= 0 && sum_v >= 0 && sum_w >= 0);
// 必ず再帰の停止条件を明記する (最初が望ましい)
if (index == max_index) {
const char *format_ok = ", total_value = %5.1f, total_weight = %5.1f\n";
const char *format_ng = ", total_value = %5.1f, total_weight = %5.1f NG\n";
bool is_not_exceed = (sum_w <= capacity); // 重さ評価のtrue/false
for (int i = 0; i < max_index; i++) {
printf("%d", flags[i]);
}
printf((is_not_exceed) ? format_ok : format_ng, sum_v, sum_w);
return (is_not_exceed) ? sum_v : 0;
}
// 以下は再帰の更新式: 現在のindex の品物を使う or 使わないで分岐し、index
// をインクリメントして再帰的にsearch() を実行する
// index番目を使わない場合
flags[index] = 0;
const double v0 = search(index + 1, list, capacity, flags, sum_v, sum_w);
// index番目を使う場合
flags[index] = 1;
Item *item = get_item(list, index);
sum_v += get_itemvalue(item);
sum_w += get_itemweight(item);
const double v1 = search(index + 1, list, capacity, flags, sum_v, sum_w);
// 使った場合の結果と使わなかった場合の結果を比較して返す
return (v0 > v1) ? v0 : v1;
}
solve関数について
solve関数はsearch関数に初期値を与えて呼び出す関数となっています。
- 0番目の品物からスタート
- 合計価値、合計重量は最初は当然ゼロ
- 品物の組み合わせを一時記録するflagsはここで定義
double solve(const Itemset *list, double capacity) {
size_t nitem = get_nitem(list);
// 品物を入れたかどうかを記録するフラグ配列 =>
// !!最大の組み合わせが返ってくる訳ではない!!
unsigned char flags[nitem];
return search(0, list, capacity, flags, 0.0, 0.0);
}
以下に取り組んでみましょう。
- 重量制限に違反する解を探索しないよう改良しましょう
- (ヒント)再帰探索の際に着目する品物をいれると重量オーバする場合にはそちら側の再帰呼び出しを実行しないようにする
- 最後に最適解を表示するように改良しましょう
- (ヒント)searchの返り値を最適値との組み合わせを表す構造体に変更する
- 該当する組み合わせはflagsから受け取るがポインタを渡すと探索中にflagsの中身が書き変わる影響をうけてしまう。
- (こちらは余力があれば行ってみてください)品物を入れるか入れないかを記録するflags を、適当なサイズの整数に置き換えてビット演算で実現してみましょう。
- 再帰を使わない場合は記録している整数を0からfor文で回せば全探索を実現できる。
- 枝刈りを行う場合は今回と同じような再帰呼び出しを考える。
Let's tryの一例
[追記] Let's try の一例を見てみましょう
枝刈り
枝刈りは品物のフラグを1にセットした際にナップサックの容量と比較して、すでに重量オーバの場合にsearchを呼び出さないようにして実現します。以下にdiffのみ示します(三項演算子を用いる)。
ソースコード
diff --git a/knapsack/src/search.c b/knapsack/src/search.c
index ab10e2b..ab67eaf 100644
--- a/knapsack/src/search.c
+++ b/knapsack/src/search.c
@@ -47,7 +47,8 @@ double search(int index, const Itemset *list, double capacity, unsigned char *fl
Item *item = get_item(list, index);
sum_v += get_itemvalue(item);
sum_w += get_itemweight(item);
- const double v1 = search(index + 1, list, capacity, flags, sum_v, sum_w);
+ bool is_not_exceed = (sum_w <= capacity);
+ const double v1 = (is_not_exceed)?search(index + 1, list, capacity, flags, sum_v, sum_w):0;
// 使った場合の結果と使わなかった場合の結果を比較して返す
return (v0 > v1) ? v0 : v1;
最適解の表示
最適解を表示する場合、再帰の末端でflagsをコピーするとともに、再帰の合流地点(品物を入れた場合と入れない場合の比較をするところ)で、使用しなかった方のflagパターンを適切にfreeします。
ソースコード
diff --git a/knapsack/include/search.h b/knapsack/include/search.h
index 7db3d46..00ab37b 100644
--- a/knapsack/include/search.h
+++ b/knapsack/include/search.h
@@ -1,8 +1,13 @@
#pragma once
#include "item.h"
+typedef struct ans{
+ double value;
+ unsigned char *flags;
+} Answer;
+
//ソルバー関数: 指定された設定でナップサック問題をとく [現状、未完成]
-double solve(const Itemset *list, double capacity);
+Answer solve(const Itemset *list, double capacity);
// solve 内で呼ぶ再帰的な探索関数 : 指定されたindex以降の組み合わせで最適な価値の総和を返す
-double search(int index, const Itemset *list, double capacity, unsigned char *flags, double sum_v, double sum_w);
+Answer search(int index, const Itemset *list, double capacity, unsigned char *flags, double sum_v, double sum_w);
diff --git a/knapsack/src/search.c b/knapsack/src/search.c
index ab67eaf..40e5274 100644
--- a/knapsack/src/search.c
+++ b/knapsack/src/search.c
@@ -8,7 +8,7 @@
#include "item.h"
// ソルバーは search を index = 0 で呼び出すだけ
-double solve(const Itemset *list, double capacity) {
+Answer solve(const Itemset *list, double capacity) {
size_t nitem = get_nitem(list);
// 品物を入れたかどうかを記録するフラグ配列 =>
@@ -18,9 +18,10 @@ double solve(const Itemset *list, double capacity) {
}
// 再帰的な探索関数
-double search(int index, const Itemset *list, double capacity, unsigned char *flags, double sum_v, double sum_w) {
+Answer search(int index, const Itemset *list, double capacity, unsigned char *flags, double sum_v, double sum_w) {
size_t max_index = get_nitem(list);
assert(index >= 0 && sum_v >= 0 && sum_w >= 0);
+ const Answer invalid = (Answer){ .value = 0, .flags = NULL}; // 解なしを定義
// 必ず再帰の停止条件を明記する (最初が望ましい)
if (index == max_index) {
@@ -28,11 +29,18 @@ double search(int index, const Itemset *list, double capacity, unsigned char *fl
const char *format_ng = ", total_value = %5.1f, total_weight = %5.1f NG\n";
bool is_not_exceed = (sum_w <= capacity); // 重さ評価のtrue/false
- for (int i = 0; i < max_index; i++) {
- printf("%d", flags[i]);
+ const char *format = (is_not_exceed)? format_ok : format_ng;
+ unsigned char *arg = (is_not_exceed)? malloc(sizeof(unsigned char) * max_index) : NULL;
+
+ if (is_not_exceed){
+ for (int i = 0; i < max_index; i++) {
+ arg[i] = flags[i];
+ printf("%d", flags[i]);
+ }
}
- printf((is_not_exceed) ? format_ok : format_ng, sum_v, sum_w);
- return (is_not_exceed) ? sum_v : 0;
+ printf(format, sum_v, sum_w);
+
+ return (is_not_exceed)?(Answer){ .value = sum_v, .flags = arg }: invalid;
}
// 以下は再帰の更新式: 現在のindex の品物を使う or 使わないで分岐し、index
@@ -40,7 +48,7 @@ double search(int index, const Itemset *list, double capacity, unsigned char *fl
// index番目を使わない場合
flags[index] = 0;
- const double v0 = search(index + 1, list, capacity, flags, sum_v, sum_w);
+ const Answer a0 = search(index + 1, list, capacity, flags, sum_v, sum_w);
// index番目を使う場合
flags[index] = 1;
@@ -48,8 +56,15 @@ double search(int index, const Itemset *list, double capacity, unsigned char *fl
sum_v += get_itemvalue(item);
sum_w += get_itemweight(item);
bool is_not_exceed = (sum_w <= capacity);
- const double v1 = (is_not_exceed)?search(index + 1, list, capacity, flags, sum_v, sum_w):0;
+ const Answer a1 = (is_not_exceed)?search(index + 1, list, capacity, flags, sum_v, sum_w): invalid;
// 使った場合の結果と使わなかった場合の結果を比較して返す
- return (v0 > v1) ? v0 : v1;
+ if ( a0.value > a1.value){
+ free(a1.flags);
+ return a0;
+ }
+ else{
+ free(a0.flags);
+ return a1;
+ }
}
diff --git a/knapsack/src/main.c b/knapsack/src/main.c
index 8aca52f..dd7af2c 100644
--- a/knapsack/src/main.c
+++ b/knapsack/src/main.c
@@ -35,11 +35,15 @@ int main(int argc, char **argv) {
print_itemset(items);
// ソルバーで解く
- double total = solve(items, W);
+ Answer ans = solve(items, W);
// 表示する
printf("----\nbest solution:\n");
- printf("value: %4.1f\n", total);
+ printf("value: %4.1f\n", ans.value);
+ for (int i = 0 ; i < get_nitem(items); i++){
+ printf("%d", ans.flags[i]);
+ }
+ printf("\n");
free_itemset(items);
return 0;
ビットを用いた全探索
ビットで表現した場合は、整数をfor文で回すだけで全ての組み合わせパターンが列挙できます。最適解を表すフラグを整数だけで表現できるのがメリットです。
ソースコード
diff --git a/knapsack/include/search.h b/knapsack/include/search.h
index 00ab37b..47a0e91 100644
--- a/knapsack/include/search.h
+++ b/knapsack/include/search.h
@@ -3,11 +3,11 @@
typedef struct ans{
double value;
- unsigned char *flags;
+ unsigned int flags; // intで管理
} Answer;
//ソルバー関数: 指定された設定でナップサック問題をとく [現状、未完成]
Answer solve(const Itemset *list, double capacity);
// solve 内で呼ぶ再帰的な探索関数 : 指定されたindex以降の組み合わせで最適な価値の総和を返す
-Answer search(int index, const Itemset *list, double capacity, unsigned char *flags, double sum_v, double sum_w);
+Answer search(int index, const Itemset *list, double capacity, unsigned int flags, double sum_v, double sum_w);
// search.c
#include "search.h"
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include "item.h"
// ソルバーは search を index = 0 で呼び出すだけ
Answer solve(const Itemset *list, double capacity) {
unsigned int flags = 0; // 32ビット;
return search(0, list, capacity, flags, 0.0, 0.0);
}
// 全探索関数
Answer search(int index, const Itemset *list, double capacity, unsigned int flags, double sum_v, double sum_w) {
const char *format_ok = ", total_value = %5.1f, total_weight = %5.1f\n";
const char *format_ng = ", total_value = %5.1f, total_weight = %5.1f NG\n";
double max_v = 0;
unsigned int max_arg = 0;
size_t nitem = get_nitem(list);
for (unsigned int i = 0 ; i < 1 << nitem ; i++){
double tmp_v = 0;
double tmp_w = 0;
for( unsigned int j = 0 ; j < nitem ; j++){
// 今回のリストの左からj番目の品物の有無を取り出す
// ビット演算だけだとどの品物かの情報も含まれているのでboolに代入
Item *item = get_item(list,j);
bool b = i & 1 << (nitem-1-j);
tmp_v += get_itemvalue(item) * b ;
tmp_w += get_itemweight(item) * b;
printf("%d", b);
}
if (tmp_w <= capacity){
printf(format_ok,tmp_v,tmp_w);
if ( tmp_v > max_v){
max_v = tmp_v;
max_arg = i;
}
}
else{
printf(format_ng,tmp_v,tmp_w);
}
}
return (Answer){ .value = max_v, .flags = max_arg};
}
diff --git a/knapsack/src/main.c b/knapsack/src/main.c
index dd7af2c..20230b8 100644
--- a/knapsack/src/main.c
+++ b/knapsack/src/main.c
@@ -40,8 +40,8 @@ int main(int argc, char **argv) {
// 表示する
printf("----\nbest solution:\n");
printf("value: %4.1f\n", ans.value);
- for (int i = 0 ; i < get_nitem(items); i++){
- printf("%d", ans.flags[i]);
+ for(int i = get_nitem(items)-1 ; i >=0 ;i--) {
+ printf("%d", (ans.flags & (1 << i))?1:0);
}
printf("\n");
ビットでのフラグ管理と枝刈り
ビットでフラグ管理した場合、プログラムの構造は配列での再帰と変わりませんが、フラグを整数で管理しているので、最適解のやりとりが少し簡単になります。search.h と main.c はビット全探索と同様です。search.c のみ、もとのコードとのdiffを示します。
ソースコード
diff --git a/knapsack/src/search.c b/knapsack/src/search.c
index 40e5274..52bbc3b 100644
--- a/knapsack/src/search.c
+++ b/knapsack/src/search.c
@@ -13,15 +13,15 @@ Answer solve(const Itemset *list, double capacity) {
// 品物を入れたかどうかを記録するフラグ配列 =>
// !!最大の組み合わせが返ってくる訳ではない!!
- unsigned char flags[nitem];
+ unsigned int flags = 0;
return search(0, list, capacity, flags, 0.0, 0.0);
}
// 再帰的な探索関数
-Answer search(int index, const Itemset *list, double capacity, unsigned char *flags, double sum_v, double sum_w) {
+Answer search(int index, const Itemset *list, double capacity, unsigned int flags, double sum_v, double sum_w) {
size_t max_index = get_nitem(list);
assert(index >= 0 && sum_v >= 0 && sum_w >= 0);
- const Answer invalid = (Answer){ .value = 0, .flags = NULL}; // 解なしを定義
+ const Answer invalid = (Answer){ .value = 0, .flags = 0}; // 解なしを定義
// 必ず再帰の停止条件を明記する (最初が望ましい)
if (index == max_index) {
@@ -30,28 +30,25 @@ Answer search(int index, const Itemset *list, double capacity, unsigned char *fl
bool is_not_exceed = (sum_w <= capacity); // 重さ評価のtrue/false
const char *format = (is_not_exceed)? format_ok : format_ng;
- unsigned char *arg = (is_not_exceed)? malloc(sizeof(unsigned char) * max_index) : NULL;
if (is_not_exceed){
- for (int i = 0; i < max_index; i++) {
- arg[i] = flags[i];
- printf("%d", flags[i]);
+ for (unsigned int i = 0 ; i < max_index ; i++){
+ printf("%d", (flags & (1 << (max_index - i - 1)))?1:0);
}
}
printf(format, sum_v, sum_w);
- return (is_not_exceed)?(Answer){ .value = sum_v, .flags = arg }: invalid;
+ return (is_not_exceed)?(Answer){ .value = sum_v, .flags = flags }: invalid;
}
// 以下は再帰の更新式: 現在のindex の品物を使う or 使わないで分岐し、index
// をインクリメントして再帰的にsearch() を実行する
// index番目を使わない場合
- flags[index] = 0;
const Answer a0 = search(index + 1, list, capacity, flags, sum_v, sum_w);
- // index番目を使う場合
- flags[index] = 1;
+ // index番目を使う場合はフラグを立てる
+ flags |= 1 << (max_index-1-index);
Item *item = get_item(list, index);
sum_v += get_itemvalue(item);
sum_w += get_itemweight(item);
@@ -59,12 +56,5 @@ Answer search(int index, const Itemset *list, double capacity, unsigned char *fl
const Answer a1 = (is_not_exceed)?search(index + 1, list, capacity, flags, sum_v, sum_w): invalid;
// 使った場合の結果と使わなかった場合の結果を比較して返す
- if ( a0.value > a1.value){
- free(a1.flags);
- return a0;
- }
- else{
- free(a0.flags);
- return a1;
- }
+ return (a0.value > a1.value)? a0 : a1;
}
より効率的な探索
ナップサック問題は、いくつか効率の良い厳密解法が知られている。
- 動的計画法を用いた解法(物の重さおよびナップサックの重量制限が整数の場合)
- 分枝限定法を用いた解法
興味がある人は調べてみましょう(発展課題)。
組み合わせ最適化: 巡回セールスマン問題
巡回セールスマン問題は都市の配置情報が与えられたときに、全ての都市を巡回する最短経路を求める問題です。ただし同じ都市を2回以上訪れてはいけないという制約があります。
サンプルプログラム
サンプルプログラムをコンパイルして実行してみましょう。
# カレントディレクトリはsoft2-lec05-srcを仮定
cd tsp
# コンパイル(bin以下に gencity, tsp がコンパイルされる)
make
# 実行前にターミナルを少し大きくしておく
# ファイルから都市の座標を読み取る
bin/tsp data/city10seed3.dat
なお現状は最短経路の計算は実装されておらず、ただ番号順に都市を回るプログラムになっています。gencity.c は乱数のシードと都市数を受け取り、都市座標を表すバイナリファイルを生成するプログラムです。引数なしで実行すると使い方が表示されます。今回のプログラムの検証に適宜用いてください。
解説
- include/src以下の3つのファイルセット
- city.h/city.c
- 町の構造体と関連関数(2都市間の距離計算およびファイルからの都市配置読み込み)
- map.h/map.c
- 描画に関する構造体と関連関数
- solve.h/solve.c
- TSPを解くための関数
- city.h/city.c
- src/main.c
- メイン関数
- data
- 都市配置のバイナリファイルを置いているディレクトリ
のようになっています。
実際にはsolve関数の中で以下に示す都市の巡回に関する配列を更新し、巡回順が確定した時点で距離を計算するプログラムになっています。
// 都市i の位置を表す構造体: 距離を計算するときに用いる
city[i];
// j番目に訪れる都市の番号: route[0] = 0 とする(必ず都市0から出発)
route[j];
// 都市の巡回順を生成する際に、都市k が巡回済みかを記録する配列
visited[k];
例えば以下に示す配列になっている場合は0->2->4->1->3->0 と巡回することになります。
route[0] = 0;
route[1] = 2;
route[2] = 4;
route[3] = 1;
route[4] = 3;
単純に全探索した場合
巡回セールスマン問題の巡回候補を列挙することは、与えられた整数列の順列を求めることに相当します。下図は都市0を出発点として都市数が4の時の巡回パターンを示したものです。
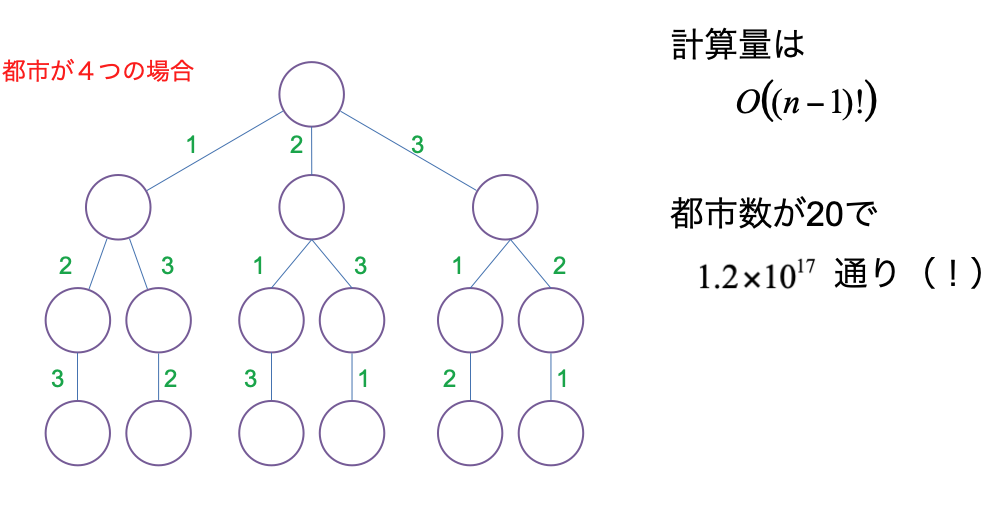
都市数が4の場合はそれほどの数ではありませんが、都市数が増えると爆発的に探索すべき候補が増えることがわかります。
TSPの全探索に入る前に
まずは[0,...,6] の整数列が与えられたときに、その順列を全て生成するプログラムを考えてみましょう。再帰を用いて記述できるはずです。
以下に取り組んでみましょう。
- permutation.c の permutation関数を完成させて [0,...,6] の順列を全て生成するプログラムを書いてみましょう。
- 順列生成を応用してITC-LMSがなかなかいえない教授bot (https://twitter.com/ITC_LMS_random) の解候補を全て生成してみましょう。
[追記] permutation.c の一例です。
#include <stdio.h>
#include <stdlib.h>
void permutation(int *pattern, int *used, size_t number);
int main(int argc, char **argv){
size_t number = 7;
int *pattern = (int*)calloc(number, sizeof(int));
int *used = (int*)calloc(number, sizeof(int));
for(int i = 0 ; i < number ; i++){
// まだパターンが確定してないことのフラグを立てておく
pattern[i] = -1;
}
permutation(pattern, used, number);
free(used);
free(pattern);
return 0;
}
void permutation(int *pattern, int *used, size_t number){
int start = -1;
for(int i = 0 ; i < number ; i++){
if (pattern[i] == -1) {
start = i;
break;
}
}
// パターンが確定した場合(再帰の終端)
if (start == -1){
printf("[ ");
for(int i = 0 ; i < number ; i++){
printf("%d ",pattern[i]);
}
printf("]\n");
return;
}
// それ以外の場合は一つパターンを確定させて再帰するのを残りの数だけ繰り返す
for (int i = 0 ; i < number ; i++){
if(!used[i]){
pattern[start] = i;
used[i] = 1;
permutation(pattern,used,number);
pattern[start] = -1;
used[i] = 0;
}
}
return ;
}
TSPの全探索にトライする
以下に取り組んでみましょう。
- solve.c 内のsolve 関数を修正し、全ての巡回パターンから最短経路を求めるように書き換えましょう。
- solve関数から、再帰的な探索関数 search を呼び出すようにする
- search は最小距離と巡回パターンをセットにした構造体Answer を返すようにする
- 巡回パターンrouteが重複なく埋まるようにする
- 未巡回の都市を選択し、訪問するパターンをチェック
- チェックし終わったらフラグを更新する
- 普通に順列を生成すると、時計回り、反時計回りは別のものとして生成され、同じ距離になる。これを枝刈りするには、例えば特定の2都市の出現順序を固定するなどするとよい(このとき間に別の都市が入るのは構わない)。たとえば、0->1->2->3->4 と 0->4->3->2->1 は同じ経路の循環方向が逆のものになる。1は必ず2の前に通るといった制約を設けることで、この2つの重複を避けることができる。
[講義後追記]
Let's try の一例
Let's try のサンプルを以下からダウンロードできます。
# wget
wget https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/soft2-lec05-tsp-example.tar.gz
# curl
curl -O https://www.gavo.t.u-tokyo.ac.jp/~dsk_saito/lecture/software2/resource/soft2-lec05-tsp-example.tar.gz
solve-pruning.c では、(次回の講義でやりますが)static 宣言子を使ってsearch関数内で現状の最小距離を保持しておくことで、途中経路まででこの最小距離を上回った場合に枝刈り処理を行っています。巡回セールスマン問題の場合、全探索は現実的ではないものの、枝刈りした場合都市数19でも30分ほど計算機が頑張れば解を探索できます(当然配置に依存します)。
山登り法
ここでは組み合わせ最適化の近似解法として山登り法を考えましょう。山登り法は以下のプロセスで解候補を修正し、探索していきます。
- 初期解を何らかの方法で生成
- 解を微修正し、より良い解に更新
- 解の改良ができなくなるまで 2 に戻り繰り返す
山登り法の特徴として
- 実装が簡単
- 最適解が求まる保証がない => 局所最適解にはまる
山登り法で最適解を求めたい場合、例えば多数の初期解から設定して得られた複数の局所最適解を最終的に比較するようなアプローチをとることになります。
巡回セールスマン問題の場合
巡回セールスマンの場合、実数のベクトルの探索と異なり、どのように巡回パターンの近傍 を定義するかが問題になります。ここでは都市の巡回パターンのうち2つの都市を入れ替えたものを考え、これを近傍とします。すなわちハミング距離が2の状態です。
これを踏まえ以下の方針で探索を行うことを考えます。
- 複数の初期解をランダムに生成する
- それぞれの初期解について
- あるパターンが与えられたときに全ての近傍パターン(2都市の入れ替え)を調べる
- 距離が最小だったパターンを採用。2-iに戻る。
- 全ての近傍より小さいパターンを見つけたら終了。局所最適解とする
- 2で得られた全ての局所最適解を比較し最適なものを解とする。
なお、巡回セールスマンにおいて、この近傍定義における局所探索(山登り法)のことを2-opt法と呼びます。これは今決まっている巡回経路のパス(枝)から隣り合わない\(k\)本を選び、繋ぎ直し可能なものを近傍とみなす\(k\)-opt法において、\(k=2\)の場合です。実用的には2-opt法か3-opt法が用いられます。
課題(締切: 01/15)
- サンプルに含まれるhelloworld.c を修正し、適切な定数値を設定することで"Hello,World" と出力するプログラムを完成させよ。出力内容はhelloworld.txt と同じものである(","の後ろにスペースはなし、改行を含む)。さらに
f[0] += ?????;に適当な定数値を設定し、"hello,World"と出力するようにせよ(最初のhが小文字に変わる)。- 最終的なプログラムはhelloworld1.c とする(定数値の設定のみ穴埋めしたコードとなる)。
- 通常、定数値を求めるためのプログラムが必要となる。このプログラムをcalc_magicnumber.c として同梱すること。
- このプログラムは非常に簡潔に書かれることを想定している。IEEE754の実装を特に考慮する必要はないが最終的に得られた結果について考察してみると面白い。
- 計算機によっては異なる結果になる可能性がある。実行した環境をコメントに記載すること。
- ディレクトリ名はhelloworldとする。
- 再帰関数を用いてフィボナッチ数列の要素 \(F_n\) を返す関数
long fibo(int n)を実装せよ。以下の点に注意し実装せよ。fibo(0) = 0 ; fibo(1) = 1;とする。n > 90についてはassertで入力を棄却してよい。出力がlongである点にも注目すること。
- 計算量オーダ(\(n\)に対しておよそどれくらいの計算時間になる指標のこと)を\( O(\log n) \) としたい。
fibo(n) = fibo(n-1) + fibo(n-2);の再帰は \( O\left(\frac{1+\sqrt 5}{2}\right)^n \) であり、効率が悪く、容易にスタックオーバーフローしうる。 - フィボナッチ数\( F_n\) は次の式を満たす。 $$ \left(\begin{array}{c}F(n)\\F(n-1)\end{array}\right) = \left(\begin{array}{cc}1&1\\1&0\\\end{array}\right)^{n-1}\left(\begin{array}{c}F(1)\\F(0)\end{array}\right)$$
- すなわち$$ A(n) = \left(\begin{array}{cc}1&1\\1&0\\\end{array}\right)^n$$ とし、この行列を効率的に求める実装を行うことになる。\(n\)が偶数のとき$$ A\left(n\right) = A\left(\frac{n}{2}\right)^2 $$となり \(n\)が奇数のとき$$ A\left(n\right) = A\left(\frac{n-1}{2}\right)^2 \left(\begin{array}{cc}1&1\\1&0\\\end{array}\right)$$ となる。
- ディレクトリ名はfibo とする。
- ナップサック問題 について、品物をバイナリファイルから読みとって探索を実行するプログラムを実装せよ。
load_itemsetというプロトタイプがあるので、活用するとよい。- バイナリは最初に品物数を表すsize_t、 そのあと価値が品物数分double で、その後重さが品物数分double で表されているとする。
- 第一引数にファイル名を受け取るようにする。第二引数に重さの上限を入力する。第一引数が数字だった場合はその数字に基づいて従来のプログラムが動くようにする。
- ディレクトリ名はknapsack1 とする。
- 巡回セールスマン問題を山登り法で解くプログラムを実装せよ。
- 都市数が20の場合の解を示すこと(tsp内のbin/gencity で都市のパターンは生成できる)
- 初期解の個数を増やしてどのような結果になるか適宜考察し、まとめる。可能であれば有効な可能性の高い初期値についても検討する。下記ディレクトリにtsp1.mdを同梱すること。
- ディレクトリ名はtsp1 とする。
- [発展課題]巡回セールスマン問題またはナップサック問題の探索アルゴリズムを改良せよ。
- 解いた問題、用いた手法とその効果を簡単に説明すること。advance.md とする。
- 例えばナップサック問題を動的計画法(DP)や分枝限定法(実数緩和して線形計画法を利用)で解く、巡回セールスマンをbit DP、3-opt法、焼きなまし法、幾何学的性質から良好な初期解を探索、遺伝的アルゴリズムで解くなどが考えられる。
- ディレクトリ名はadvance とする。
ディレクトリ構成およびMakefile
- 基本課題のみの場合はSOFT-12-26-NNNNNNNN 以下にhelloworld, fibo, knapsack1, tsp1というディレクトリ、発展課題も提出の場合は それに加えてadvanceというディレクトリを作成する
- それぞれのディレクトリにコンパイル用のMakefileを作成し同梱せよ
- make clean も実装すること
- 提出前にmake clean しておく(= バイナリは同梱しない)
- 追加のデータファイルがある場合はそれも同梱せよ
提出方法
- UTOLにて提出する
- 全てのプログラム/ファイルをまとめ、zip またはtar.gzで圧縮し提出
- 必ずREADME.md を同梱し、やった内容を簡潔に記述する
- ファイル名は
SOFT-12-26-NNNNNNNN.zipまたはSOFT-12-26-NNNNNNNN.tar.gzとする- NNNNNNNN部分は学籍番号(ハイフンは除く)
- JについてはJ??????? のようにする
- 課題について
- 基本課題は毎回提出
- 発展課題は成績計算に全6回中上位3回分を採用する