峯松・齋藤研究室 五月祭展示
東京大学本郷キャンパス
概要
2026年5月16日(土)・17日(日) 9:00 ~ 18:00
五月祭にて研究室公開デモ展示を行います。
アクセス
東京大学本郷キャンパス 工学部2号館 10階 103C1, 103C2
東京大学大学院工学系研究科 電気系工学専攻 峯松・齋藤研究室
発表紹介

音響音声学のいろは 〜初めて音声波形を見る方へ〜
ショートレクチャー

峯松研究室 (Prof. Minematsu) Minematsu Laboratory
ポスター

Improve your spoken English with STEAC! Special Training for English Academic Communication
ポスター
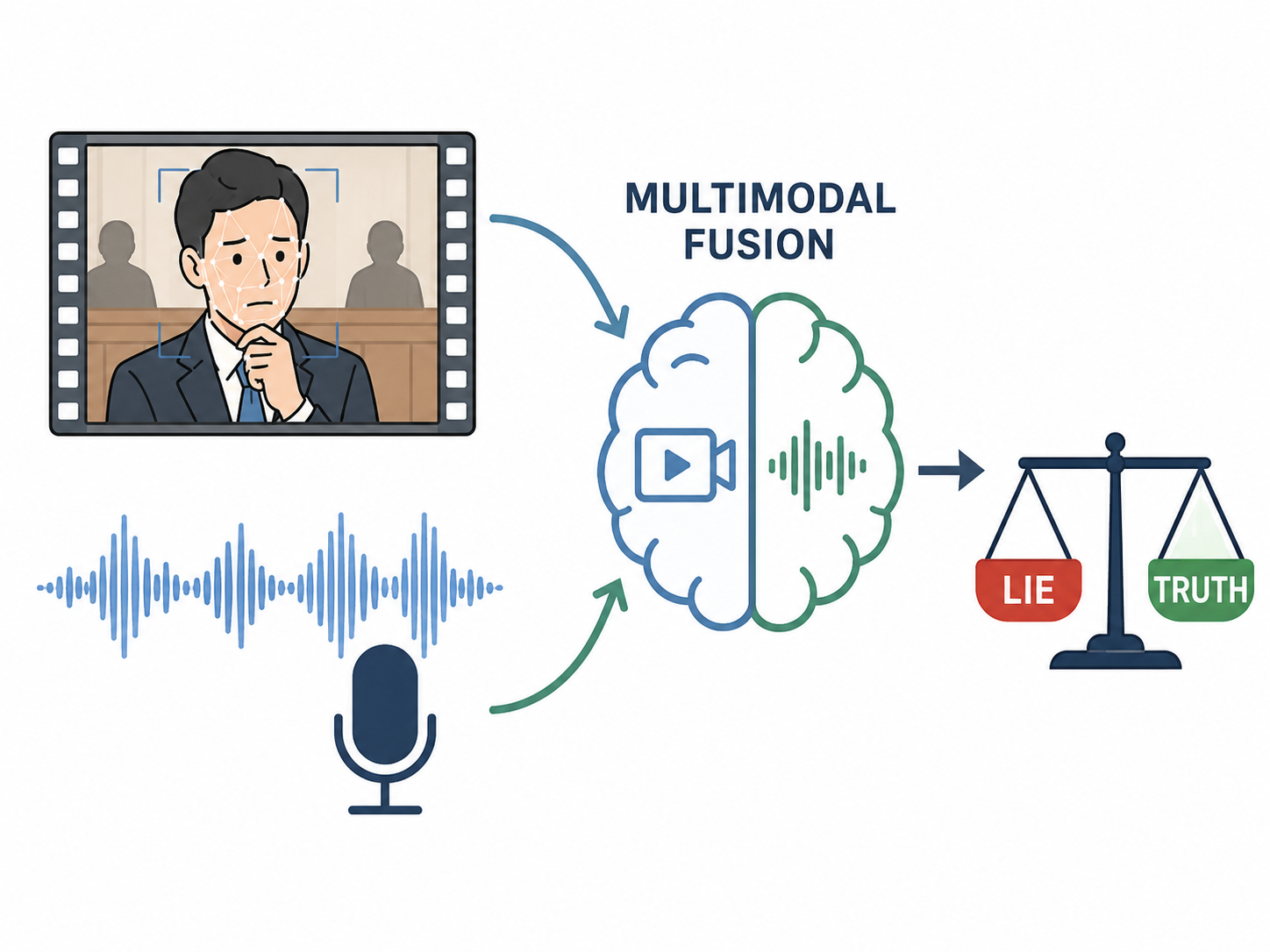
Lie Detection Based on Multimodal Fusion: A Case Study of Court Trial Video Dataset
既卒 徐婷 ポスター

Incorporating Respect into LLM-Based Academic Feedback: A BI-R Framework for Instructing Students after Q&A Sessions
既卒 相場真由子 ポスター

世界諸英語話者間の相互シャドーイングに基づく聴取崩れの要因分析
既卒 藤原朱里 ポスター
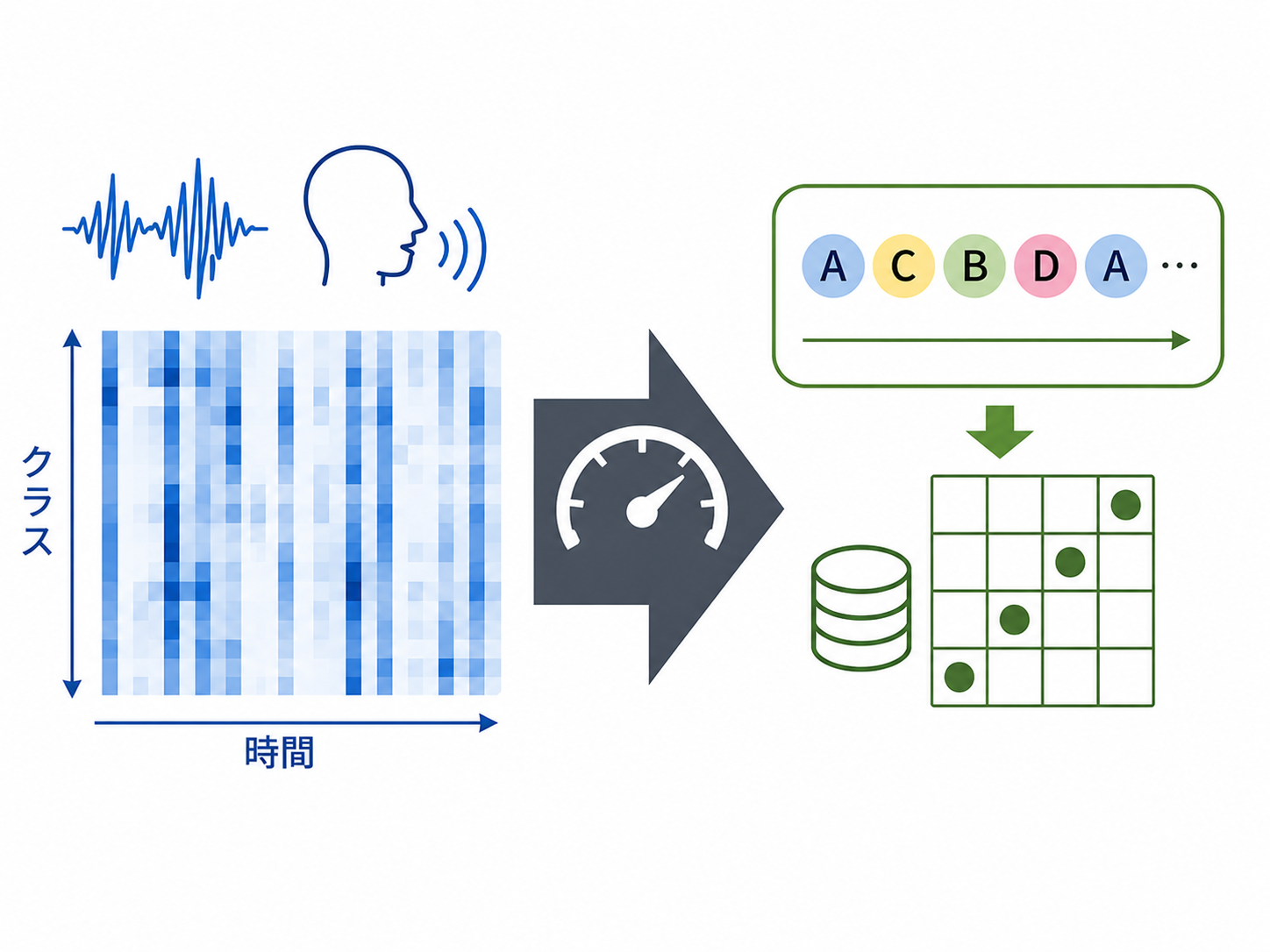
後部確率グラムに基づくDTWの高速化: 後部確率を算出する分類器に内在するクラス間距離の蒸留による手法
D1 孫海童 ポスター

英語リスニング支援に向けたモデル音声中の音声変化の定量的検出法とその効果に関する検討
既卒 山本和季 ポスター

LangInLab: Augmenting Engineering Lab Instruction with Vision- and Voice-Enabled AI Agents for Language Learning
既卒 鴫正典 ポスター
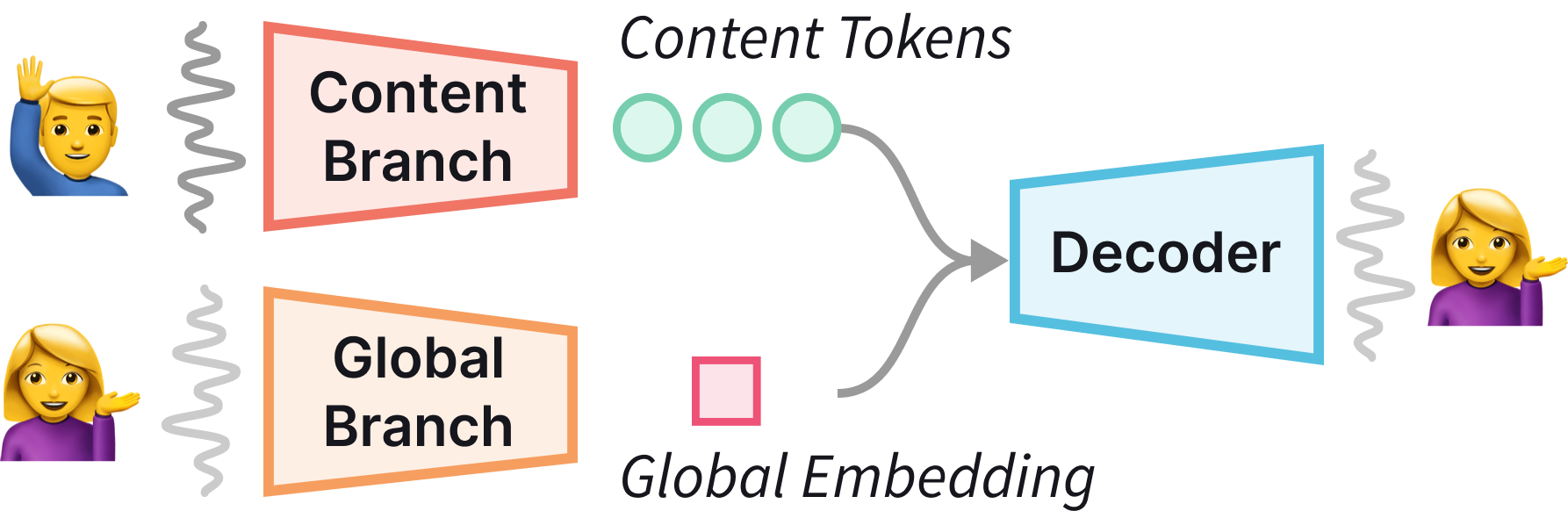
Kanade: A Simple Disentangled Tokenizer for Spoken Language Modeling
M2 黄治杰 デモあり
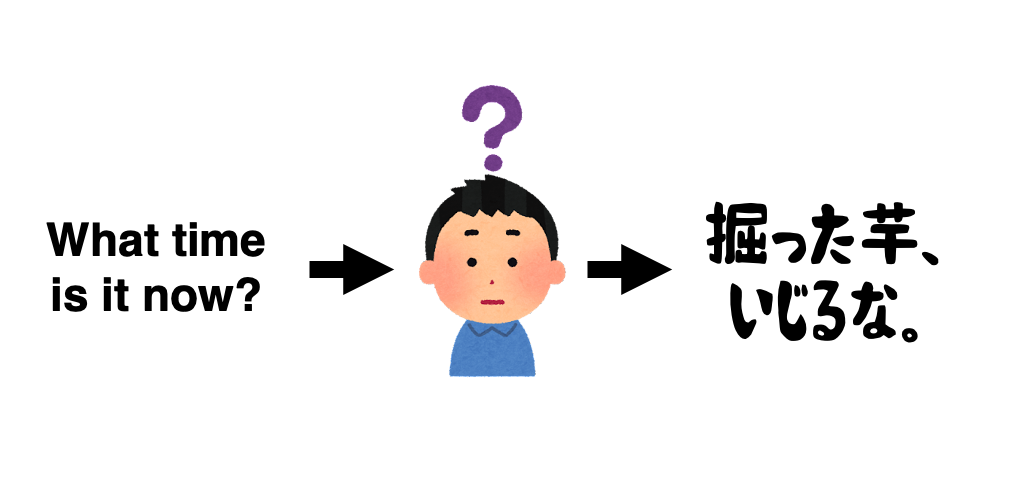
音声離散トークンを活用した母語話者音声のみによる外国語訛り音声の合成
D1 恩田健太郎 デモあり

人間の知覚特性の再現に基づく母語話者音声のみを用いた外国語訛り音声認識
D1 恩田健太郎 ポスター
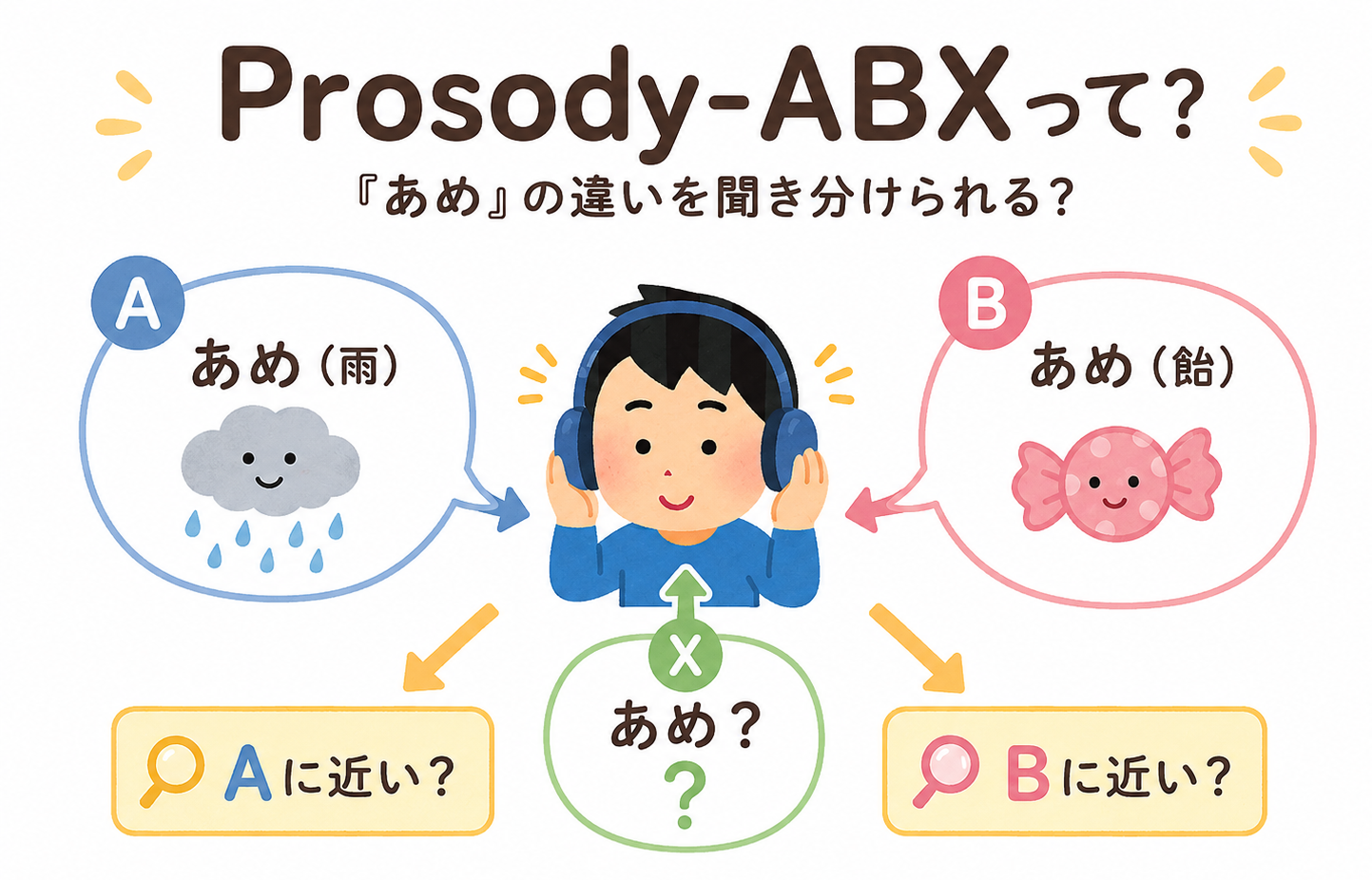
日本語・英語・中国語の「アクセント」の違い、聞き分けられる? 音声モデルと一緒にProsody-ABXテストに挑戦!
D1 孫海童 ポスター

Synthesizing True Golden Voices to Enhance Pronunciation Training for Individual Language Learners
M2 山中涼雅 ポスター
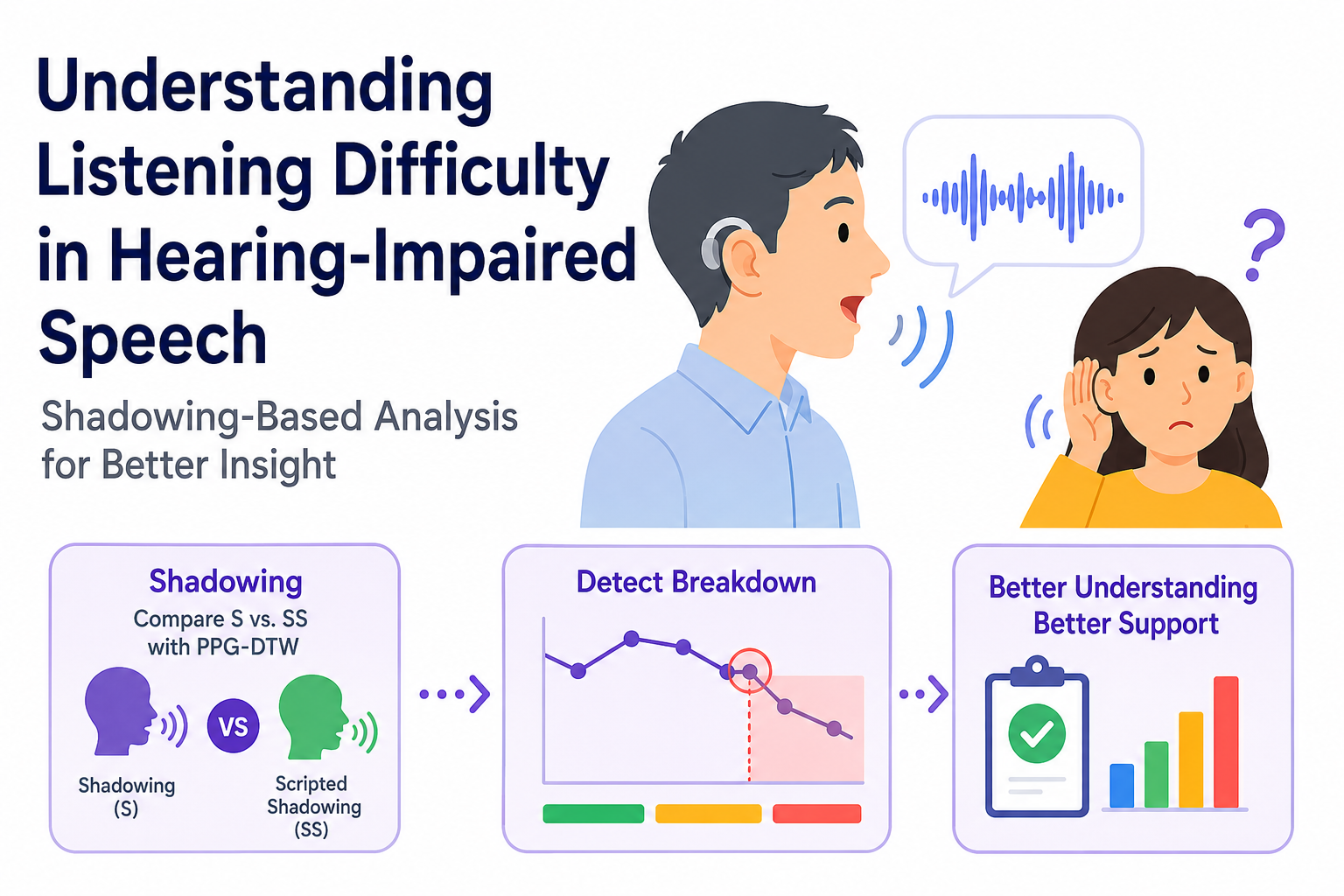
シャドーイングを用いた難聴者発話に対する健聴者の聴取困難の分析
D2 勝間田里菜 ポスター

シャドーイングによる聞き取り困難症者の聴取困難度計測に向けた試み
D2 勝間田里菜 ポスター
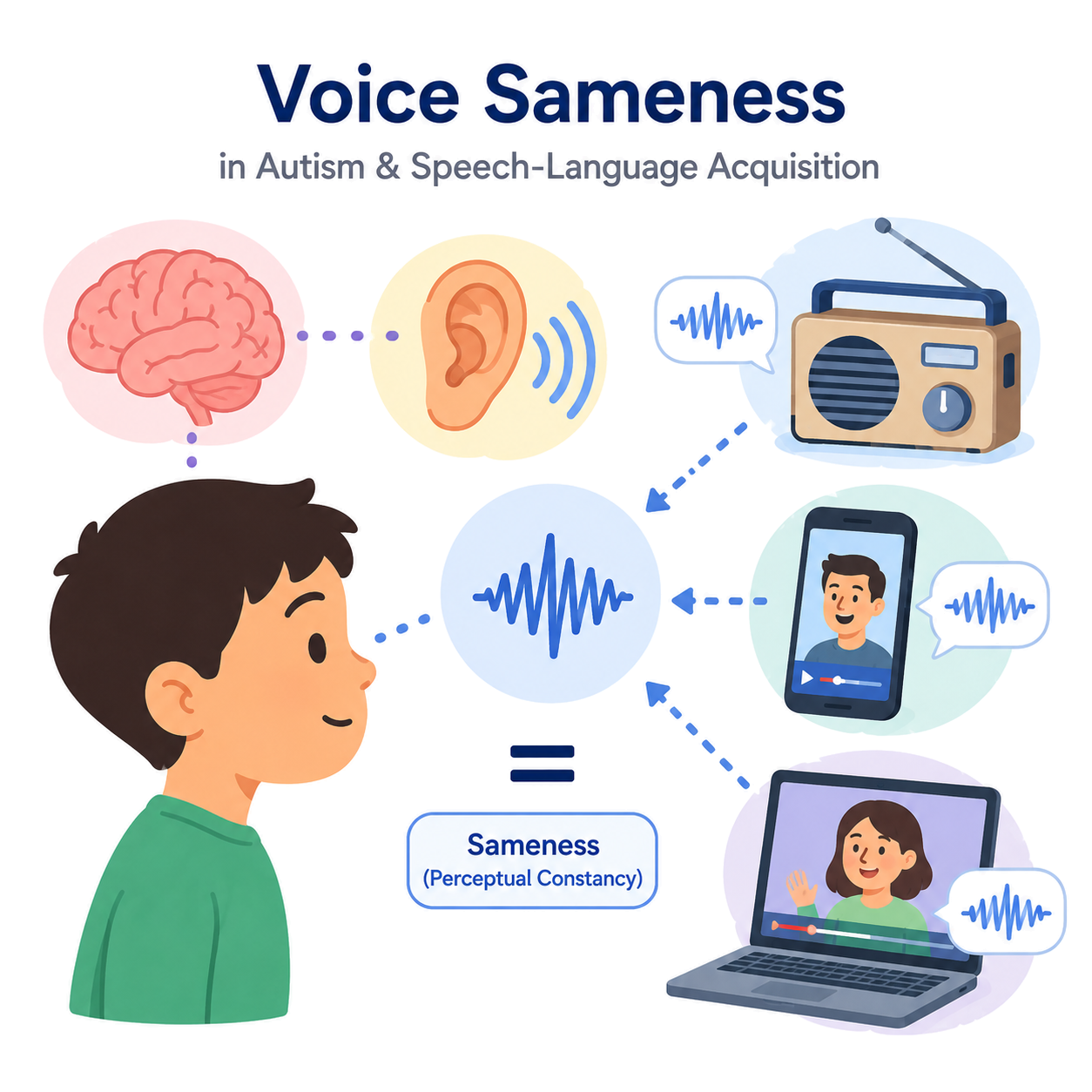
自閉症と音声言語獲得に関する理論研究
ポスター
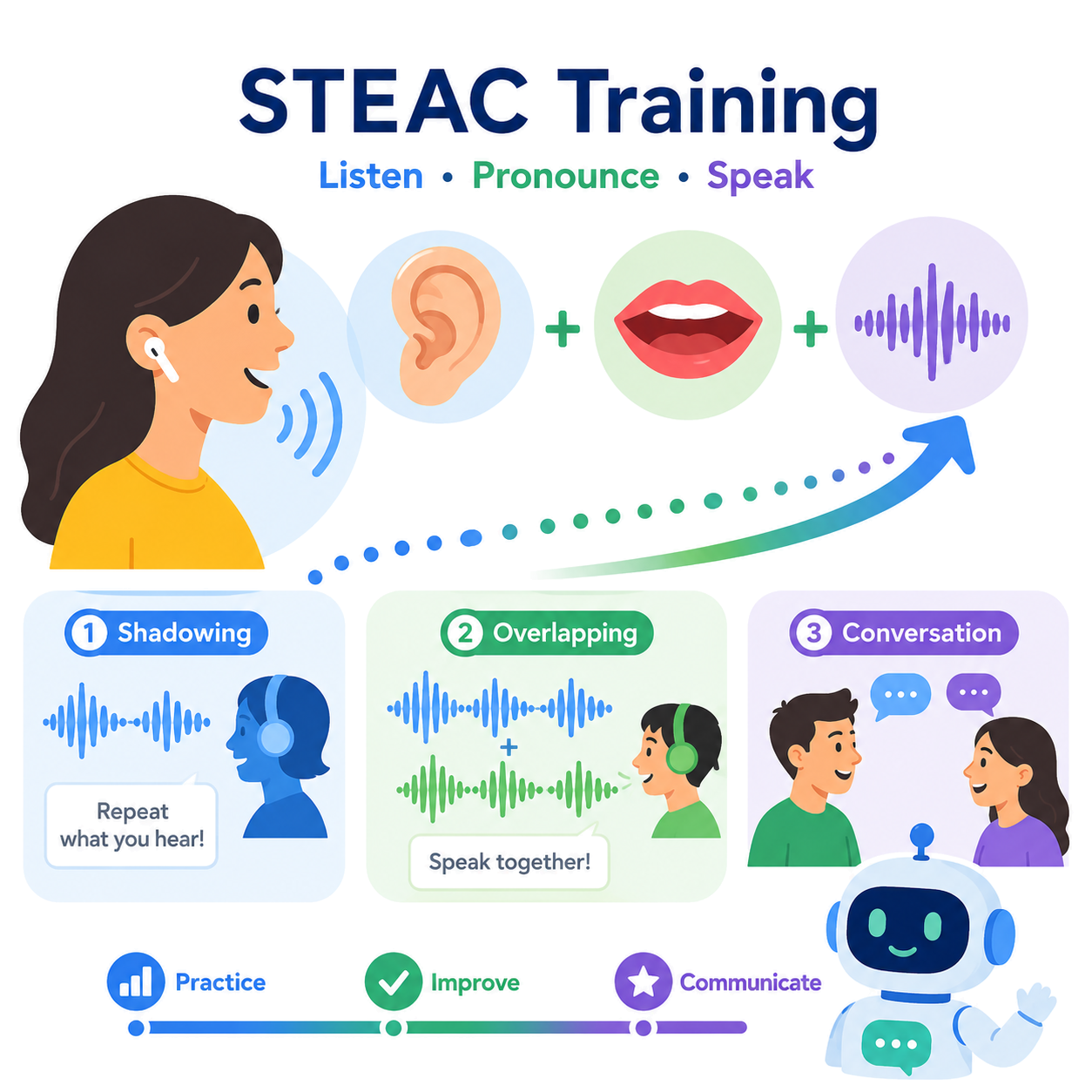
聴取力&発音力強化 in STEAC
デモあり
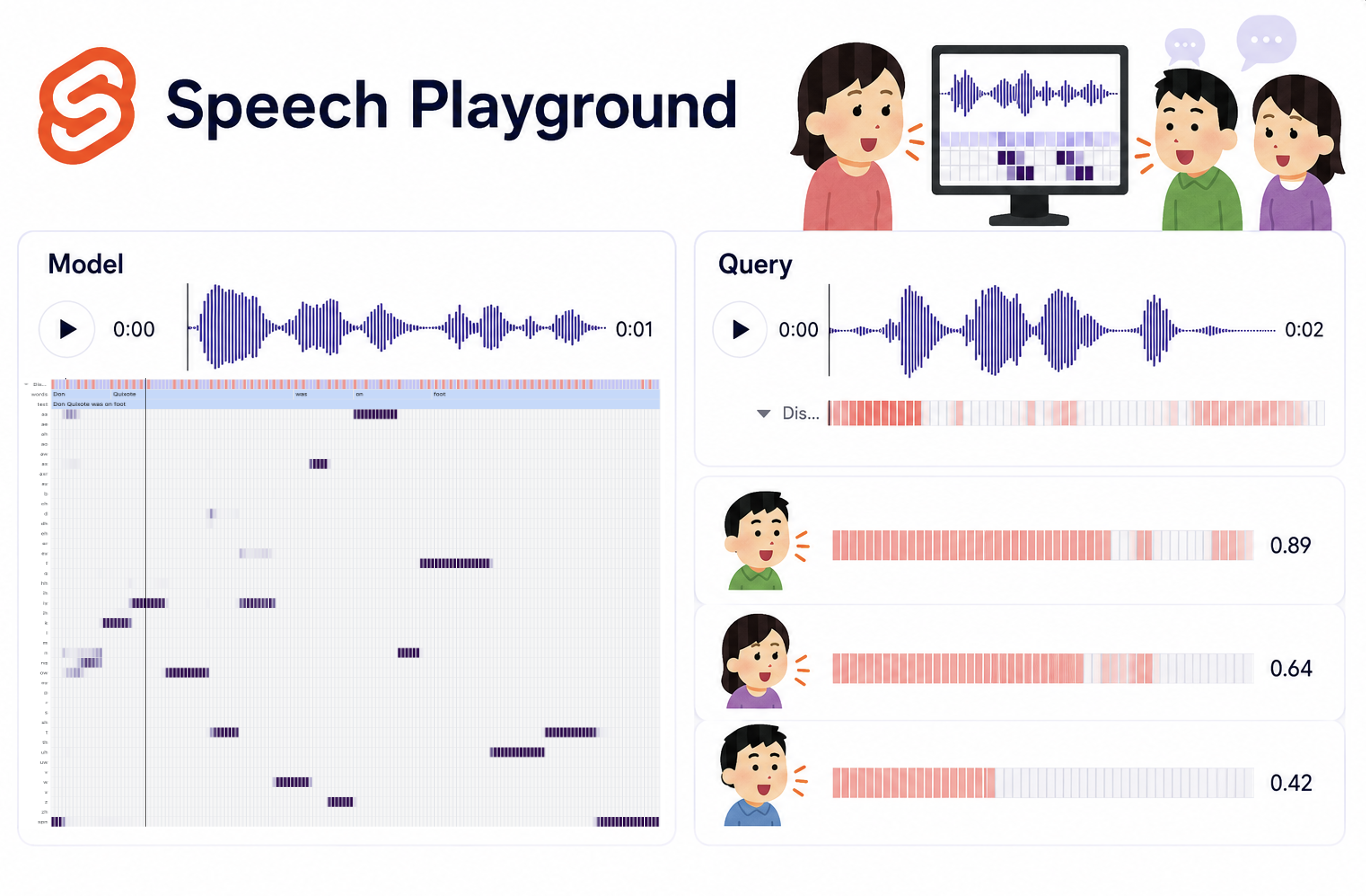
Speech Playground: 音声の分析・比較のためのインタラクティブツール
M2 Stephen McIntosh デモあり

AURORA, STEAC, そしてSTEAC for Xへ
ポスター

ChatGPT英会話+自動評価
デモあり

LangInLab
デモあり

Beyond Acoustic Sparsity and Linguistic Bias: A Prompt-Free Paradigm for Mispronunciation Detection and Diagnosis
D3 耿浩彭 デモあり

日本語韻律読み上げチュータ・スズキクン
デモあり
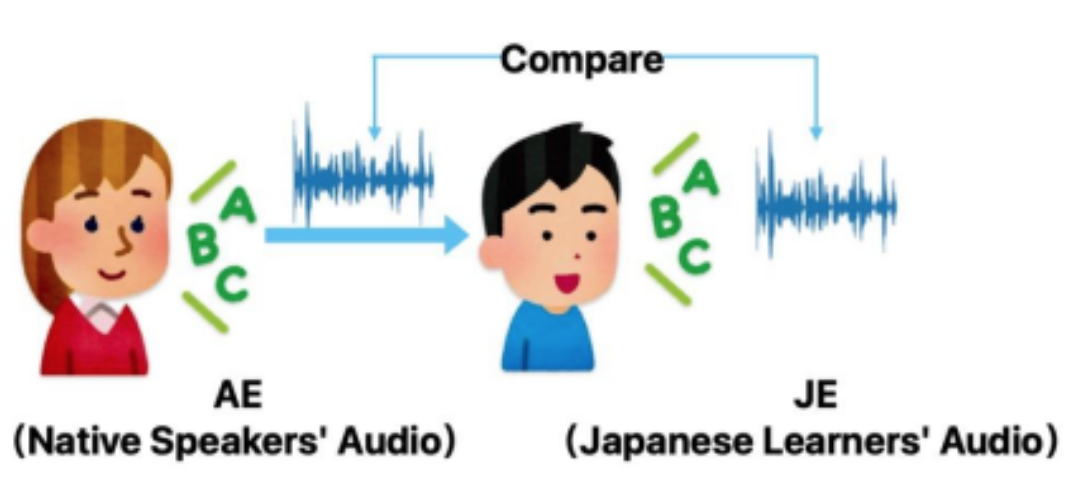
Analyzing and Predicting Prosodic Challenges for Japanese Students to Learn Oral English
既卒 程禧瑷 ポスター

STEACの横・斜・縦展開
ポスター

シャドーイングに基づくジャズ聴取能力の定量的評価とその学習効果の検証
既卒 宮城瑠翔 デモあり
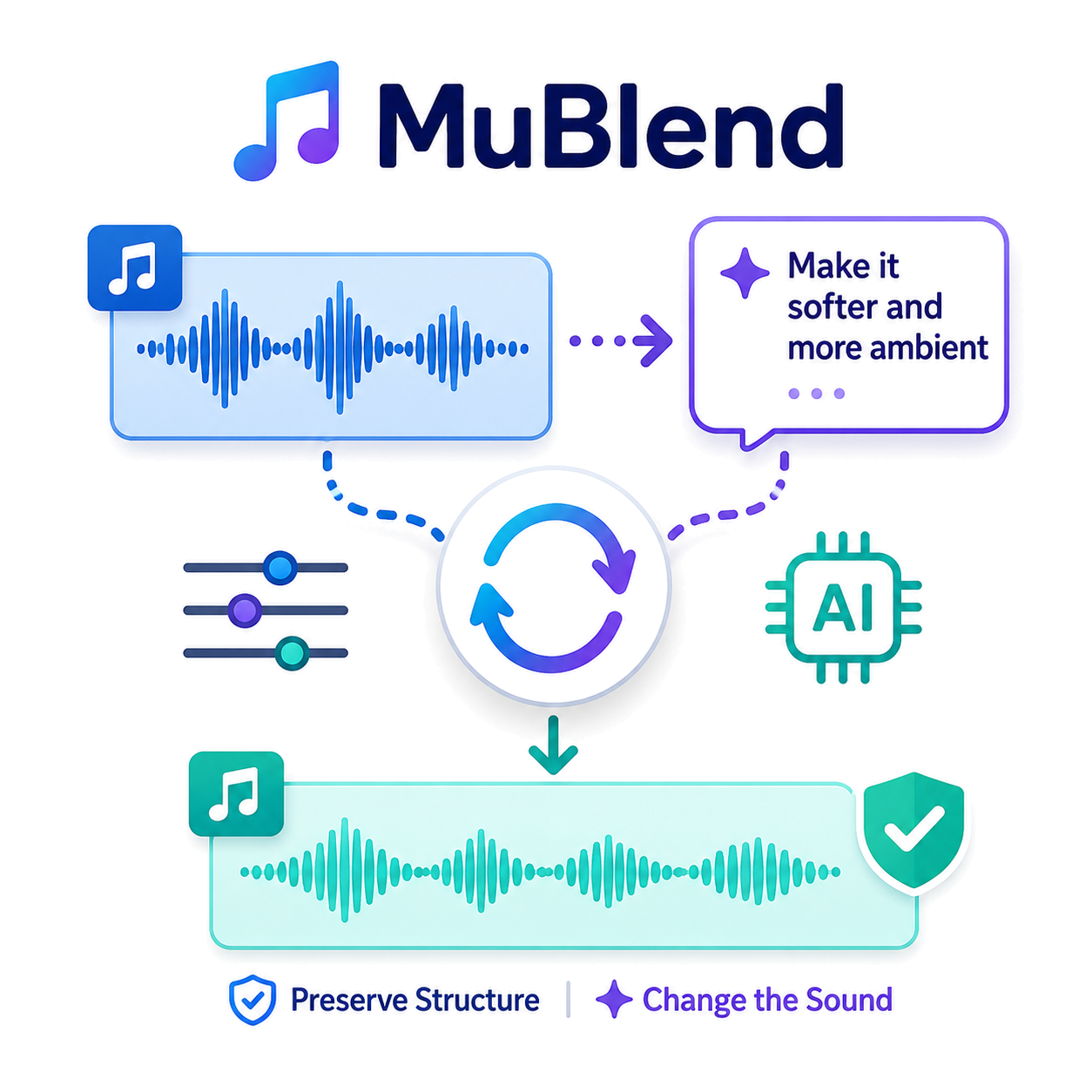
MuBlend: Training-Free Text-Guided Music Editing via Dual Progressive Inversion-State Blending
M2 邵佳禾 デモあり

歌唱者間の相互作用と個人性を考慮した斉唱音声合成のための音高制御モデルの検討
M1 馬場開仁 デモあり

最大公約基本周波数に基づく重唱音声のソース・フィルタ分析と和音制御
既卒 福地柊斗 デモあり
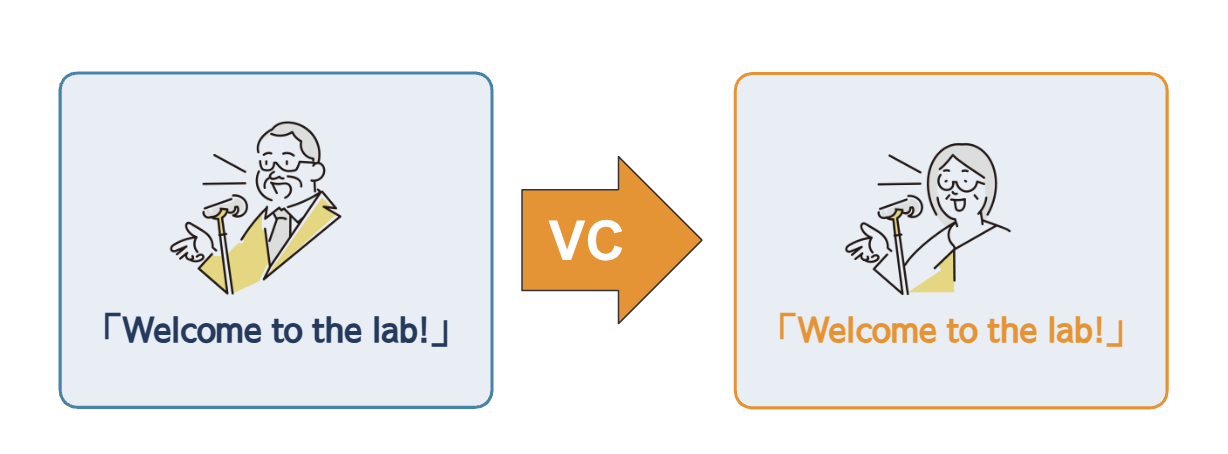
ガウス混合モデルによる局所線形変換を用いた自己教師あり音声表現に基づく声質変換
M1 田名部智也 デモあり
効果音制作に向けた微分可能シンセサイザーによるサウンドマッチングに関する検討
M2 曺龍平 デモあり

話者認証に対する敵対的攻撃における入力音源特性の影響に関する分析
既卒 川原大樹 ポスター

PINNsを用いた声区識別のための歌声特徴量抽出手法の検討
M2 斎木陵佑 ポスター

Switch Whisper: Adapting Whisper for Code-Switching ASR by Mixture-of-LoRA-Experts
M2 汪国濤 ポスター
音響印象予測モデルに基づく環境音の印象分布分析とText-to-Audioモデルの印象制御の検討
D1 西島大史 ポスター

Transformer型音声認識器におけるエンコーダ先読み情報を活用したデコーディング手法の検討
既卒 岡田翔太 ポスター

顔画像から想起される声の印象に関する分析
既卒 宮本蓮 ポスター
Research on Conversion of Japanese Dialects
D2 張何畏 ポスター
