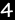
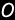
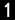
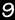
















Request
About the speech samples
This accent dictionary has been developed as a tool to facilitate Japanese pronunciation education. A number of conjugated forms of words have been covered with all of these forms being accompanied by speech samples. As of August, 2012, we are providing male and female speech samples for a total 42,300 conjugated forms of words.
The speakers are professional voice actors. We recorded this speech using a word list in which the accent kernel position was given for each word. When recording, both the speaker and recorded paid mind to the accent type to ensure the highest of quality for the recordings. Though the correct accent types were given for the words, among the samples, there are some in which the accent kernel was not perceived as being in the desirable location. (Examples are given below). Also, there were some cases in which automatic segmentation of speech samples did not segment the recording with the correct boundaries. In addition, the male speaker pronounced 'u' as a voiced vowel in some cases where it should not have been. We plan to rerecord such undesirable samples.
あやしくない,おかしくなかった,たのしければ
Such samples are not desirable to use as model speech for learners. To find such samples, it will be necessary to listen to all of the samples and remove any erroneous ones manually.
In total, there are 3500 words (12 forms, 2 speakers). If the samples are broken into sets of 100, it will be necessary to have 35 people listen to them. We are in the process of developing a web environment to listen to and inspect the samples. For this, now we are looking for volunteers to assist us in the process of locating such samples. Supposing one word (including all the conjugated forms) takes one minute, it should require about two hours to complete the inspection of one group.
To continue our quest to maintain the highest quality, we would appreciate it if those interested in this inspection would contact here.
OJAD Project Leader: Nobuaki Minematsu (University of Tokyo)